⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬、关注🤝,关注必回关
上一篇文章已经跟大家介绍过《决策树(上):数据挖掘十大算法之一》,相信大家对决策树(上)都有一个基本的认识。下面我讲一下:决策树(中):数据挖掘十大算法之一。
一、分类树和回归树
基于信息度量的不同方式,我们可以把决策树分为 ID3 算法、C4.5 算法和 CART 算法。今天我来带你学习 CART 算法。CART 算法,英文全称叫做 Classification And Regression Tree,中文叫做分类回归树。ID3 和 C4.5 算法可以生成二叉树或多叉树,而 CART 只支持二叉树。同时 CART 决策树比较特殊,既可以作分类树,又可以作回归树。
那么你首先需要了解的是,什么是分类树,什么是回归树呢?
我用下面的训练数据举个例子,你能看到不同职业的人,他们的年龄不同,学习时间也不同。如果我构造了一棵决策树,想要基于数据判断这个人的职业身份,这个就属于分类树,因为是从几个分类中来做选择。如果是给定了数据,想要预测这个人的年龄,那就属于回归树。
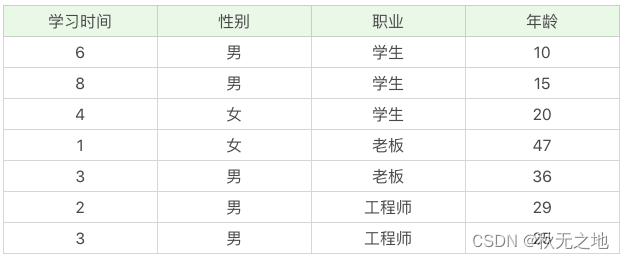
分类树可以处理离散数据,也就是数据种类有限的数据,它输出的是样本的类别,而回归树可以对连续型的数值进行预测,也就是数据在某个区间内都有取值的可能,它输出的是一个数值。
二、CART 分类树的工作流程
决策树的核心就是寻找纯净的划分,因此引入了纯度的概念。在属性选择上,我们是通过统计“不纯度”来做判断的,ID3 是基于信息增益做判断,C4.5 在 ID3 的基础上做了改进,提出了信息增益率的概念。实际上 CART 分类树与 C4.5 算法类似,只是属性选择的指标采用的是基尼系数。
你可能在经济学中听过说基尼系数,它是用来衡量一个国家收入差距的常用指标。当基尼系数大于 0.4 的时候,说明财富差异悬殊。基尼系数在 0.2-0.4 之间说明分配合理,财富差距不大。
基尼系数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。所以 CART 算法在构造分类树的时候,会选择基尼系数最小的属性作为属性的划分。
我们接下来详解了解一下基尼系数。基尼系数不好懂,你最好跟着例子一起手动计算下。
假设 t 为节点,那么该节点的 GINI 系数的计算公式为:
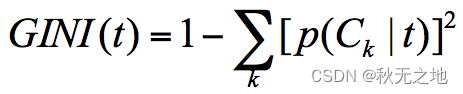
这里 p(Ck|t) 表示节点 t 属于类别 Ck 的概率,节点 t 的基尼系数为 1 减去各类别 Ck 概率平方和。
通过下面这个例子,我们计算一下两个集合的基尼系数分别为多少:
集合 1:6 个都去打篮球;
集合 2:3 个去打篮球,3 个不去打篮球。
针对集合 1,所有人都去打篮球,所以 p(Ck|t)=1,因此 GINI(t)=1-1=0。
针对集合 2,有一半人去打篮球,而另一半不去打篮球,所以,p(C1|t)=0.5,p(C2|t)=0.5,GINI(t)=1-(0.5*0.5+0.5*0.5)=0.5。
通过两个基尼系数你可以看出,集合 1 的基尼系数最小,也证明样本最稳定,而集合 2 的样本不稳定性更大。
在 CART 算法中,基于基尼系数对特征属性进行二元分裂,假设属性 A 将节点 D 划分成了 D1 和 D2,如下图所示:
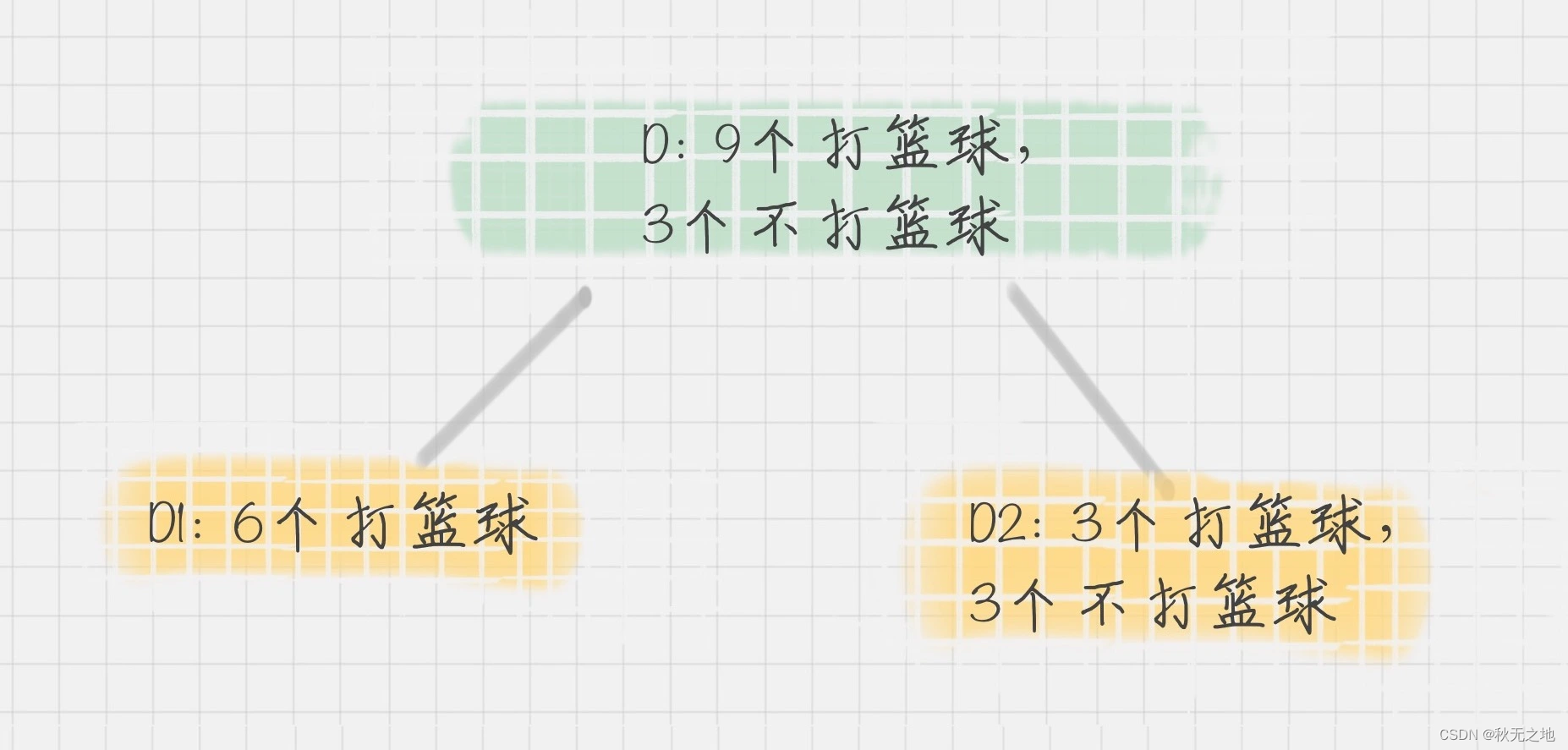
节点 D 的基尼系数等于子节点 D1 和 D2 的归一化基尼系数之和,用公式表示为:
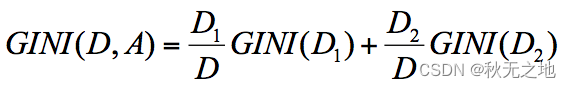
归一化基尼系数代表的是每个子节点的基尼系数乘以该节点占整体父亲节点 D 中的比例。
上面我们已经计算了集合 D1 和集合 D2 的 GINI 系数,得到:
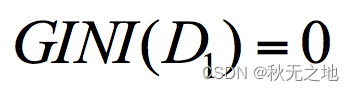
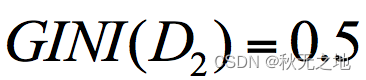
所以在属性 A 的划分下,节点 D 的基尼系数为:
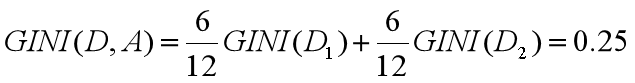
节点 D 被属性 A 划分后的基尼系数越大,样本集合的不确定性越大,也就是不纯度越高。
三、如何使用 CART 算法来创建分类树
通过上面的讲解你可以知道,CART 分类树实际上是基于基尼系数来做属性划分的。在 Python 的 sklearn 中,如果我们想要创建 CART 分类树,可以直接使用 DecisionTreeClassifier 这个类。创建这个类的时候,默认情况下 criterion 这个参数等于 gini,也就是按照基尼系数来选择属性划分,即默认采用的是 CART 分类树。
下面,我们来用 CART 分类树,给 iris 数据集构造一棵分类决策树。iris 这个数据集,我在 Python 可视化中讲到过,实际上在 sklearn 中也自带了这个数据集。基于 iris 数据集,构造 CART 分类树的代码如下:
# encoding=utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 准备数据集
iris=load_iris()
# 获取特征集和分类标识
features = iris.data
labels = iris.target
# 随机抽取33%的数据作为测试集,其余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
# 创建CART分类树
clf = DecisionTreeClassifier(criterion='gini')
# 拟合构造CART分类树
clf = clf.fit(train_features, train_labels)
# 用CART分类树做预测
test_predict = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, test_predict)
print("CART分类树准确率 %.4lf" % score)运行结果:
CART分类树准确率 0.9600如果我们把决策树画出来,可以得到下面的图示:
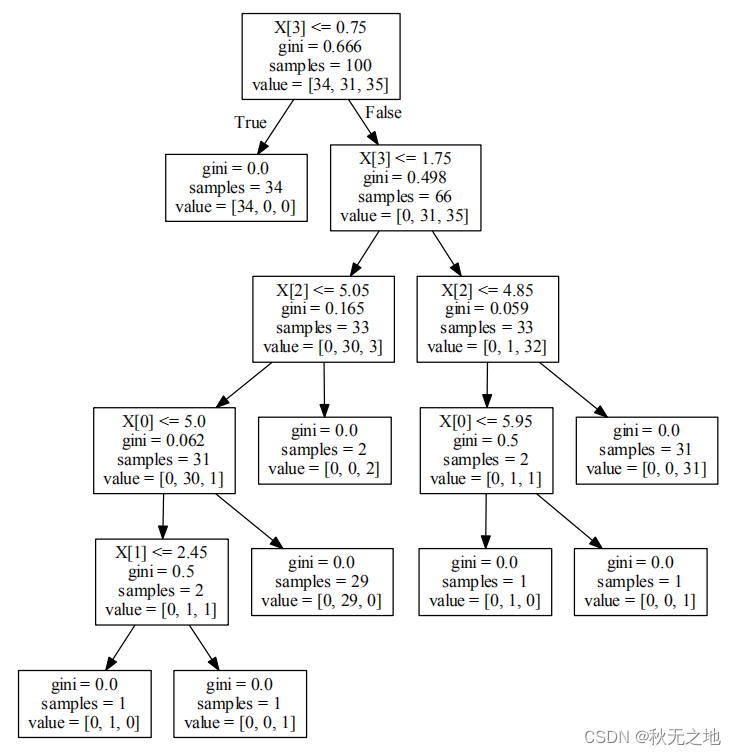
首先 train_test_split 可以帮助我们把数据集抽取一部分作为测试集,这样我们就可以得到训练集和测试集。
使用 clf = DecisionTreeClassifier(criterion=‘gini’) 初始化一棵 CART 分类树。这样你就可以对 CART 分类树进行训练。
使用 clf.fit(train_features, train_labels) 函数,将训练集的特征值和分类标识作为参数进行拟合,得到 CART 分类树。
使用 clf.predict(test_features) 函数进行预测,传入测试集的特征值,可以得到测试结果 test_predict。
最后使用 accuracy_score(test_labels, test_predict) 函数,传入测试集的预测结果与实际的结果作为参数,得到准确率 score。
我们能看到 sklearn 帮我们做了 CART 分类树的使用封装,使用起来还是很方便的。
四、CART 回归树的工作流程
CART 回归树划分数据集的过程和分类树的过程是一样的,只是回归树得到的预测结果是连续值,而且评判“不纯度”的指标不同。在 CART 分类树中采用的是基尼系数作为标准,那么在 CART 回归树中,如何评价“不纯度”呢?实际上我们要根据样本的混乱程度,也就是样本的离散程度来评价“不纯度”。
样本的离散程度具体的计算方式是,先计算所有样本的均值,然后计算每个样本值到均值的差值。我们假设 x 为样本的个体,均值为 u。为了统计样本的离散程度,我们可以取差值的绝对值,或者方差。
其中差值的绝对值为样本值减去样本均值的绝对值:
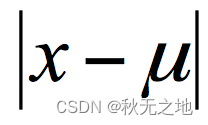
方差为每个样本值减去样本均值的平方和除以样本个数:
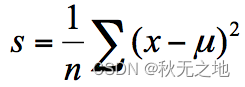
所以这两种节点划分的标准,分别对应着两种目标函数最优化的标准,即用最小绝对偏差(LAD),或者使用最小二乘偏差(LSD)。这两种方式都可以让我们找到节点划分的方法,通常使用最小二乘偏差的情况更常见一些。
我们可以通过一个例子来看下如何创建一棵 CART 回归树来做预测。
五、如何使用 CART 回归树做预测
这里我们使用到 sklearn 自带的波士顿房价数据集,该数据集给出了影响房价的一些指标,比如犯罪率,房产税等,最后给出了房价。
根据这些指标,我们使用 CART 回归树对波士顿房价进行预测,代码如下:
# encoding=utf-8
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
from sklearn.tree import DecisionTreeRegressor
# 准备数据集
boston=load_boston()
# 探索数据
print(boston.feature_names)
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取33%的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33)
# 创建CART回归树
dtr=DecisionTreeRegressor()
# 拟合构造CART回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price)) 运行结果(每次运行结果可能会有不同):
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT']
回归树二乘偏差均值: 23.80784431137724
回归树绝对值偏差均值: 3.040119760479042如果把回归树画出来,可以得到下面的图示(波士顿房价数据集的指标有些多,所以树比较大):

上图文件下载路径点这里
我们来看下这个例子,首先加载了波士顿房价数据集,得到特征集和房价。然后通过 train_test_split 帮助我们把数据集抽取一部分作为测试集,其余作为训练集。
使用 dtr=DecisionTreeRegressor() 初始化一棵 CART 回归树。
使用 dtr.fit(train_features, train_price) 函数,将训练集的特征值和结果作为参数进行拟合,得到 CART 回归树。
使用 dtr.predict(test_features) 函数进行预测,传入测试集的特征值,可以得到预测结果 predict_price。
最后我们可以求得这棵回归树的二乘偏差均值,以及绝对值偏差均值。
我们能看到 CART 回归树的使用和分类树类似,只是最后求得的预测值是个连续值。
六、CART 决策树的剪枝
CART 决策树的剪枝主要采用的是 CCP 方法,它是一种后剪枝的方法,英文全称叫做 cost-complexity prune,中文叫做代价复杂度。这种剪枝方式用到一个指标叫做节点的表面误差率增益值,以此作为剪枝前后误差的定义。用公式表示则是:
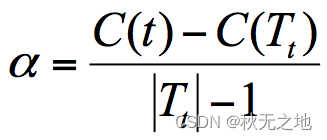
其中 Tt 代表以 t 为根节点的子树,C(Tt) 表示节点 t 的子树没被裁剪时子树 Tt 的误差,C(t) 表示节点 t 的子树被剪枝后节点 t 的误差,|Tt|代子树 Tt 的叶子数,剪枝后,T 的叶子数减少了|Tt|-1。
所以节点的表面误差率增益值等于节点 t 的子树被剪枝后的误差变化除以剪掉的叶子数量。
因为我们希望剪枝前后误差最小,所以我们要寻找的就是最小α值对应的节点,把它剪掉。这时候生成了第一个子树。重复上面的过程,继续剪枝,直到最后只剩下根节点,即为最后一个子树。
得到了剪枝后的子树集合后,我们需要用验证集对所有子树的误差计算一遍。可以通过计算每个子树的基尼指数或者平方误差,取误差最小的那个树,得到我们想要的结果。
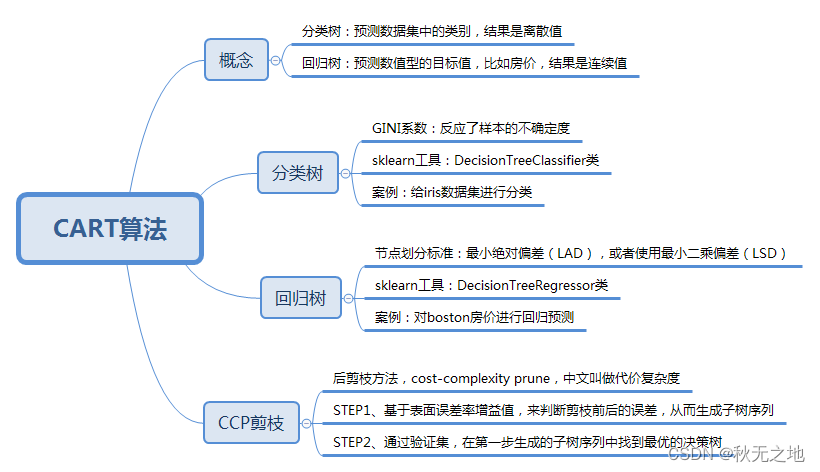
四、总结
三种决策树之间在属性选择标准上的差异:
- ID3 算法,基于信息增益做判断;
- C4.5 算法,基于信息增益率做判断;
- CART 算法,分类树是基于基尼系数做判断。回归树是基于偏差做判断。
下面是CART算法的总结:
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。










