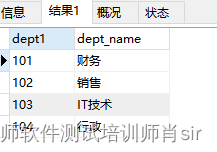
已知2张基本表:部门表:dept (部门号,部门名称);员工表 emp(员工号,员工姓名,年龄,入职时间,收入,部门号)
1:dept表中有4条记录:
部门号(dept1) 部门名称(dept_name )
101 财务
102 销售
103 IT技术
104 行政
2:emp表中有6条记录:
员工号 员工姓名 年龄 入职时间 收入 部门号对应字段名称为: (sid name age worktime_start incoming dept2)
1789 张三 35 1980/1/1 4000 101
1674 李四 32 1983/4/1 3500 101
1776 王五 24 1990/7/1 2000 101
1568 赵六 57 1970/10/11 7500 102
1564 荣七 64 1963/10/11 8500 102
1879 牛八 55 1971/10/20 7300 103
1.列出每个部门的平均收入及部门名称;
结果:avg(incomig) dept_mame
条件 :每个部门 ,平均收入
语句: group by avg
思路:先左连接,在分组group by 分组部门, 求的结果 avg(incoming)平均工资和部门名称
方法1:
select dept_name,avg(incoming) FROM dept left join emp on dept.dept1=emp.dept2 GROUP BY dept_name;
2.财务部门的收入总和;
结果:sum(incoming)
条件:dept_name=财务, 收入总和
语句: dept_name=‘财务’ ,sum(incoming)等于财务部门,在结果输出:sum(incoming)
思路:先内连接合表,where 条件
方法1:select sum(incoming) from dept INNER JOIN emp on dept.dept1=emp.dept2 where dept_name=‘财务’;
方法2:select sum(incoming) from emp where dept2 = (select dept1 from dept where dept_name = ‘财务’);
方法3:SELECT SUM(a.incoming) FROM (SELECT incoming FROM dept inner join emp on dept.dept1=emp.dept2 where dept_name=“财务”)a ;
3.It技术部入职员工的员工号
结果:sid(emp)
条件:dept_name=‘it技术部门’ (dept)
语句: dept_name=‘it技术部门’
思路:先内连接,where 条件dept_name=‘it技术部门’ ,显示结果sid
方法1:
select sid from dept INNER JOIN emp ON dept1=dept2 where dept_name=“IT技术”;
方法2:
select sid from emp where dept2 =(select dept1 from dept where dept_name=“IT技术”)
4.财务部门收入超过2000元的员工姓名
结果:name
条件: 财务部门, 超过2000元
语句:dept_name=财务,incoming>2000
思路:先两表联合,where dept_name=‘财务’ and incoming >2000
方法1:select name from dept left join emp on dept.dept1=emp.dept2 where incoming>2000 and dept_name=“财务” ;
方法2:子查询
select sid from emp where incoming>2000 and dept2=(select dept1 from dept where dept_name=‘财务’)
思路 :
先找出 dept_name=财务 ,财务部门的部门编号 101dpet1中 ;在到emp中作为条件
在emp中找出收入2000;
(1)select dept1 from dept where dept_name=‘财务’
(2)select sid from emp where incoming>2000 and dept2=(select dept1 from dept where dept_name=‘财务’)
5.找出销售部收入最低的员工的入职时间;
结果:入职时间
条件: 销售部 最低的收入
语句:dept_name="销售’ min(incoming)
思路: 先合表 where 销售部门 and 销售部门最低工资 ,结果显示入职时间
方法1: select worktime_start from emp,dept where incoming=(select min(incoming) from emp,dept where dept1=dept2 and dept_name=‘销售’) and dept_name=‘销售’;
注意点:找出销最低的薪资工资(7500)
select min(incoming) from emp inner join dept on dept1=dept2 where dept_name=‘销售’
6.找出年龄小于平均年龄的员工的姓名,ID和部门名称
结果:name、sid、dpte_name
条件:小于平均年龄
语句:age <avg(age)
方法1:select name,sid,dept_name from emp INNER JOIN dept on dept.dept1=emp.dept2 where age < (select avg(age) from emp);
7.列出每个部门收入总和高于9000的部门名称
结果:部门名称 dept_name
条件:收入总和 ,收入总和>9000 ,每个部门
语句:sum incoming)、 having sum incoming)>9000 ,group by dept_name
方法1:SELECT s.dept_name from (select dept_name,sum(incoming)as s from dept INNER JOIN emp on dept.dept1=emp.dept2 group by dept_name HAVING s >9000)s ;
方法2:
select dept_name from dept INNER JOIN emp on dept.dept1=emp.dept2 group by dept_name HAVING sum(incoming) >9000;
方法3:
select dept_name from dept inner join (select dept2,sum(incoming) from emp2 group by dept2 having sum(incoming)>9000)a on dept1=dept2;
将如下两张表合表
方法4:
select d.dept_name from emp t,dept d where d.dept1 = t.dept2 and dept2 in
(select dept2 from emp group by dept2 having sum(incoming) > 9000 ) group by d.dept_name;
方法5:
select DISTINCT(d.dept_name) from emp t,dept d where d.dept1 = t.dept2 and dept2 in
(select dept2 from emp group by dept2 having sum(incoming) > 9000 ) ;
方法6:
select dept_name from dept where dept1 in
(select dept2 from emp group by dept2 having sum(incoming) > 9000 ) ;

8.查出财务部门工资少于3800元的员工姓名
结果:员工姓名 name
条件:财务 工资<3800
语句: dept_name=‘财务’ ,incoming <3800
思路:先合表,where 财务部门 and incoming <3800
方法1
select name from dept inner join emp on dept.dept1=emp.dept2 where dept_name=“财务” and incoming< 3800 ;
方法2:
select name FROM emp where dept2=(select dept1 FROM dept where dept_name=“财务”)and incoming <3800 ;
9.求财务部门最低工资的员工姓名;
结果: name
条件:财务部门 ,最低工资
语句:dept_name=‘财务’ min(incoming)
思路:先合表 ,where dept_name=‘财务’ and min(incoming)
方法1:select name from emp,dept where incoming=(select min(incoming) from emp,dept where dept1=dept2 and dept_name=‘财务’) and dept_name=‘财务’;
方法2:(弊端:当有两个同样的最低数据,只能显示第一个)
SELECT emp.name from emp where emp.dept2=(SELECT dept.dept1 from dept where dept.dept_name=‘财务’) order by emp.incoming asc LIMIT 0,1
方法3:(缺陷)
select name from emp inner join dept on emp.dept2=dept.dept1 where dept_name=‘财务’ order by incoming limit 0,1 ;
10.找出销售部门中年纪最大的员工的姓名
结果:姓名 name
条件: 销售部 、年纪最大
语句:dept_name=销售 ,max(age)
思路:先合表,where dept_name=销售 and max(age)
方法1:select name from dept inner JOIN emp on dept.dept1=emp.dept2 where dept_name=“销售” and age=(select max(age) from dept left join emp on dept.dept1=emp.dept2 where dept_name=“销售” ) ;
11.求收入最低的员工姓名及所属部门名称:
结果:name ,dept _name
条件:收入
语句: min(incoming)
思路:先合表 where 最低工资
方法1:select name,dept_name from emp,dept where incoming=(select min(incoming) from emp) and dept1=dept2;
方法2:SELECT name,dept_name from dept inner JOIN emp on dept.dept1=emp.dept2 where incoming=(select min(incoming) from dept left join emp on dept.dept1=emp.dept2 ) ;
12.求李四的收入及部门名称
结果:incoming、dept_name
条件:name=李四
语句: where name=‘李四’
思路:合表 where 接条件: name=‘李四’
方法1:select incoming,dept_name from emp,dept where dept1=dept2 and name=‘李四’;
方法2:select dept_name,incoming from dept inner join emp on dept.dept1=emp.dept2 where name=‘李四’
13.求员工收入小于4000元的员工部门编号及其部门名称
结果:dept1或dept2 ,dept_name
条件: 收入<4000
语句:incoming<4000
思路:先合表 where 接条件incoming<4000
方法1:select dept1,dept_name from emp,dept where dept1=dept2 and incoming<4000;
14.列出每个部门中收入最高的员工姓名,部门名称,收入,并按照收入降序;
结果:员工姓名name,部门名称 dept_name,收入 incoming
条件:每个部门 ,收入最高 ,降序
语句: group by ,max(incoming),order by desc
思路:先合表, in 【先合表, 分组 having max(incomig) 】 查询结果:员工姓名name,部门名称 dept_name,收入 incoming
方法1:
select name,dept_name,incoming from dept LEFT JOIN emp on dept.dept1=emp.dept2 where (dept_name,incoming) in (select dept_name ,max(incoming) from dept LEFT JOIN emp on dept.dept1=emp.dept2 group by dept_name) ORDER BY incoming desc ;
方法2:
select name,dept_name,incoming from ( select * from dept LEFT JOIN emp on dept.dept1=emp.dept2 ORDER BY incoming desc) a GROUP BY a.dept_name ORDER BY a.incoming desc
15.求出财务部门收益最高的俩位员工的姓名,工号,收益
结果:姓名name,工号 ,收益
条件: 财务部门,收益最高,俩位
语句:dept_name=‘财务’, max(incoming),limit 0,2
思路:先合表,wehre 条件1dept_name=‘财务’ 降序 ,取两位, 显示姓名,工号,收益
方法1:select name,sid,incoming from emp,dept where dept2=dept1 and dept_name=‘财务’ order by incoming desc limit 0,2;
方法2:select name,sid,incoming FROM dept INNER JOIN emp on dept.dept1=emp.dept2 where dept_name=“财务” ORDER BY incoming desc LIMIT 2;
16.查询财务部低于平均收入的员工号与员工姓名:
结果:员工号 sid,员工姓名 name
条件:财务部 ,低于平均收入
语句:dept _name=‘财务’, avg(incoming)>age
思路:合表,where dept _name='财务 and incoming<(平均工资)
方法1:
select sid,name from emp,dept where incoming<(select avg(incoming) from emp) and dept2=dept1 and dept_name=‘财务’;
方法2:
SELECT name,sid FROM dept left join emp on dept.dept1=emp.dept2 WHERE dept_name=“财务” and incoming<
(SELECT AVG(incoming) FROM dept left join emp on dept.dept1=emp.dept2)
方法3:
select sid,name from dept inner JOIN emp on dept.dept1=emp.dept2 where dept_name=“财务” and incoming<(select avg(incoming) from emp) ;
17.列出部门员工数大于1个的部门名称;
结果:部门名称 dept_name
条件:员工数大于1
语句: dept_name ,count(name)>1
思路:合表 where 条件 count>1
方法1:select a.dept_name from(SELECT dept_name,COUNT(name) s FROM dept left join emp on dept.dept1=emp.dept2 GROUP BY dept_name HAVING COUNT(name) >1 )a
方法2:
SELECT dept_name FROM dept INNER JOIN emp on dept.dept1=emp.dept2 GROUP BY dept_name having count(dept_name) >1
方法3:
SELECT dept_name FROM dept where dept1 in (select dept2 from emp group by dept2 having count(name)>1 ) ;
18.列出部门员工收入不超过7500,且大于3000的员工年纪及部门编号;
结果:年纪 、编号
条件:收入不超过7500、大于3000
语句:incoming>=7500 and incoming>3000
思路:
1 、先合表where 条件(incoming>=7500 and incoming>3000),显示:age、dept2
2、emp表where (incoming>=7500 and incoming>3000),显示:age、dept2
方法1:select age,dept2 from emp where incoming<=7500 and incoming>3000;
方法2:select age,dept2 from emp inner join dept on dept.dept1=emp.dept2 where incoming<=7500 and incoming>3000;
方法3:
select age,sid from Testemp where incoming between 3001 and 7500;
19.求入职于20世纪70年代的员工所属部门名称;
结果:部门名称 (dept)
条件:入职20世纪70年代 (emp)
语句:worktime_start like “197%” 或者 worktime_start >=1970 and worktime_start <=1979
思路:先合表 where worktime_start like “197%” ,查询结果:dept_name
方法1:SELECT DISTINCT(dept_name) FROM dept INNER JOIN emp on dept.dept1=emp.dept2 WHERE worktime_start BETWEEN 1970 AND 1979;
方法2:
SELECT dept.dept_name from emp LEFT JOIN dept on dept.dept1=emp.dept2 where
emp.worktime_start like ‘197%’;
方法3:
SELECT dept_name FROM dept INNER JOIN emp on dept.dept1=emp.dept2 where worktime_start>“1970-01-01” AND worktime_start<“1980-01-01”;
20.查找张三所在的部门名称;
结果:部门名称
条件:张三
语句:name=“张三”
思路:先合表, where
select dept_name from dept,emp where dept2=dept1 and name=‘张三’;
21.列出每一个部门中年纪最大的员工姓名,部门名称;
结果:员工姓名,部门名称
条件:每一个部门\年纪最大
语句:group by max(age)
思路:
方法1:
SELECT name,dept_name FROM dept INNER JOIN emp on dept.dept1=emp.dept2 where age in(SELECT max(age) from dept INNER JOIN emp on dept.dept1=emp.dept2 GROUP BY dept_name)
方法2:
22.列出每一个部门的员工总收入及部门名称;
结果:员工总收入 ,部门名称
条件:每一个部门、总收入
语句:group buy ,sum (incoming)
方法:合表, 分组 ,用行数sum求出总数据线显示,部门名称
方法1:select dept_name,sum(incoming) from emp left join dept ON dept.dept1=emp.dept2 group by dept_name
23.列出部门员工收入大于7000的员工号,部门名称;
结果:员工号,部门名称
条件:收入大于7000
语句: incoming>7000
思路:合表where incoming>7000 显示sid、depta_name
方法1:SELECT sid,dept_name FROM dept right JOIN emp on dept.dept1=emp.dept2 WHERE incoming>7000
24.找出哪个部门还没有员工入职;
结果: 部门
条件:没有员工入职
语句: is null dept_name
思路:左连接 where 右表字段为null
方法1:sELECT dept_name FROM dept left JOIN emp on dept.dept1=emp.dept2 WHERE sid is null
方法2:select dept_name from (select * from emp right join dept on dept1=dept2) a where a.sid is null;
方法3:SELECT dept_name from emp RIGHT JOIN dept on dept.dept1=emp.dept2 GROUP BY dept.dept_name HAVING COUNT(emp.dept2)=0
25.先按部门号大小排序,再依据入职时间由早到晚排序员工信息表 ;
结果: 员工信息表 (*)
条件:部门号大小排序,早到晚
语句: order by desc ,asc
思路:合表, 排序(order by )dcs , worktime asc
方法1:SELECT * FROM dept right JOIN emp on dept.dept1=emp.dept2 ORDER BY dept1 desc , worktime_start asc
方法2:select * from emp order by dept2 asc, worktime_start asc;
26.求出财务部门工资最高员工的姓名和员工号
结果: 姓名、员工号
条件:财务部门、工资最高、
语句: dept_name=“财务”、max(incoming)
思路:合表、wehre dept_name=“财务” and 财务最高工资
方法1:
SELECT name,sid FROM dept inner JOIN emp on dept.dept1=emp.dept2 WHERE dept_name=“财务” and incoming=
(SELECT MAX(incoming) FROM dept inner JOIN emp on dept.dept1=emp.dept2 WHERE dept_name=“财务”)
方法2:
select sid,name from dept inner JOIN emp on dept.dept1=emp.dept2 where dept_name=“财务” order by incoming desc limit 1 ;
27.求出工资在7500到8500之间,年龄最大的员工的姓名和部门名称。
结果: 姓名、部门名称
条件:工资在7500到8500、年龄最大
语句: incoming >=7500 and incoing<=8500 或between 7500and 8500 ;max(age)
思路:合表 where 条件(ncoming >=7500 and incoing<=8500) and 年龄最大
方法1:
SELECT name,dept_name FROM
dept inner JOIN emp on dept.dept1=emp.dept2 WHERE age=
(SELECT MAX(age) FROM emp WHERE incoming BETWEEN 7500 AND 8500) and incoming BETWEEN 7500 AND 8500 ;
方法2:
select t.name,d.dept_name from emp t,dept d where d.dept1 = t.dept2 AND
(d.dept1,t.age) = (select dept2,max(age) from emp where incoming between 7500 and 8500 group by dept2);
注意点:
1、as 别名 可以省略不写
2、在 select 显示字段中只能显示函数或 group by 分组 后的字段 ;其他字段都是默认取第一行
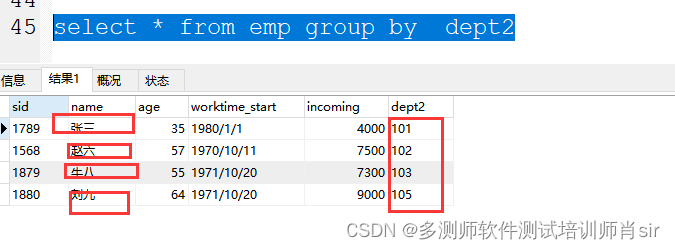
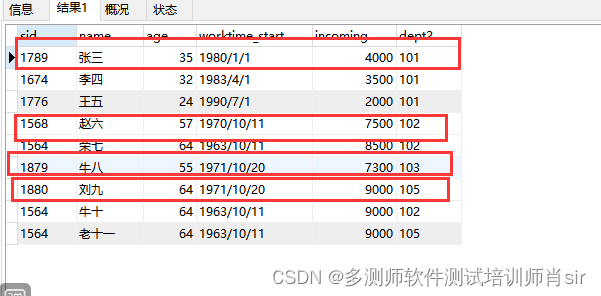
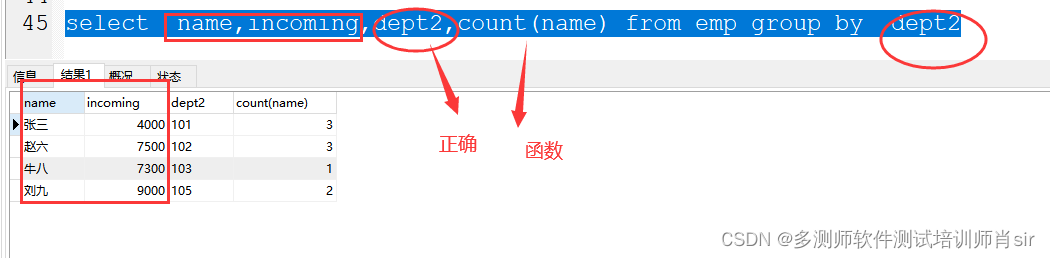
3、在求最低或最高的数据时,使用limit 的方法有缺陷,就是当数据有重复的,只能显示一个








