Mybatis学习笔记10 高级映射及延迟加载_biubiubiu0706的博客-CSDN博客
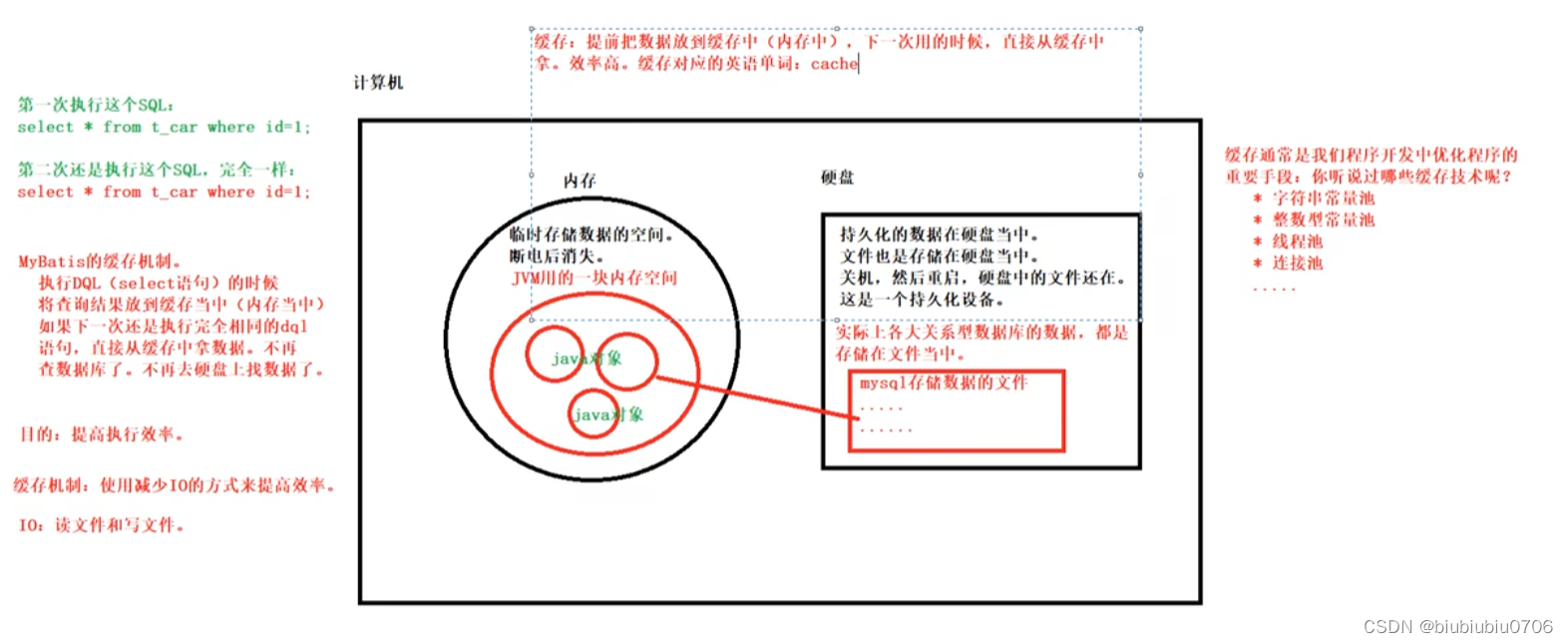
缓存:cache
缓存的作用:通过减少IO的方式,来提高程序的执行效率
Mybatis的缓存:将select语句的查询结果放到缓存(内存)当中,下一次还是这条select语句的话,直接从缓存中取,不再查数据库.一方面是减少了IO.另一方面不再执行繁琐的查找算法.提高效率.
Mybatis自带的缓存机制包括:
一级缓存:将查询到的数据存储到SqlSession中.
二级缓存:将查询到的数据存储到SqlSessionFactory中.
或者集成其他第三方的缓存:比如EhCache(Java语言开发的),Memcache(C语言开发的)等
SqlSession和SqlSessionFactory的生命周期
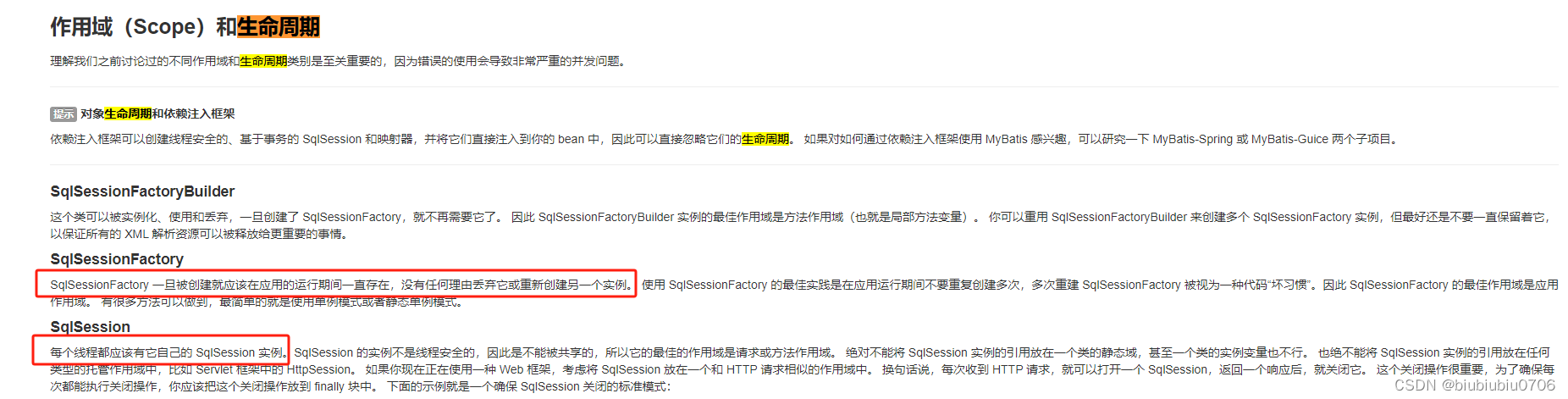
SqlSessionFactory:一旦被创建就应该在应用的运行期间一直存在.
SqlSession:每一个线程都应该有它自己的SqlSession实例.
那么一级缓存就是说一个线程内的多次的相同查询会被缓存.也就是说只针对当前会话.而且默认开启
而二级缓存是存放在SqlSessionFactory中的.那么会在整个应用访问期间一直存在
Mybatis中的缓存只针对DQL语句,也就是说缓存机制只对应select语句
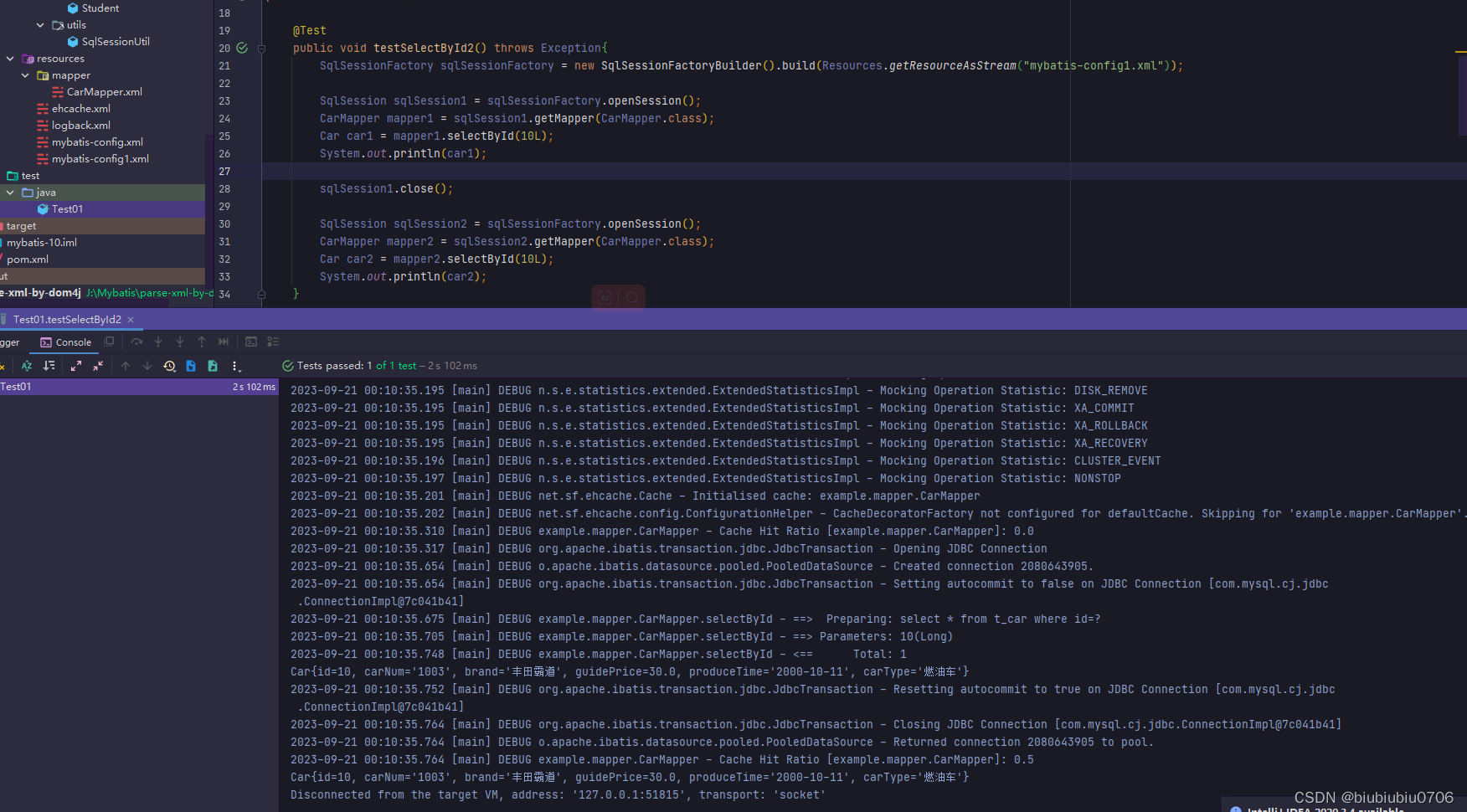
先来看一个例子,这是上篇结尾的测试
大概目录结构 进行测试

1.一级缓存
Mybatis中一级缓存默认开启,不需要任何配置.
只要使用同一个SqlSession对象执行同一条SQL语句,就会走缓存.

查数据库没有的


再测试

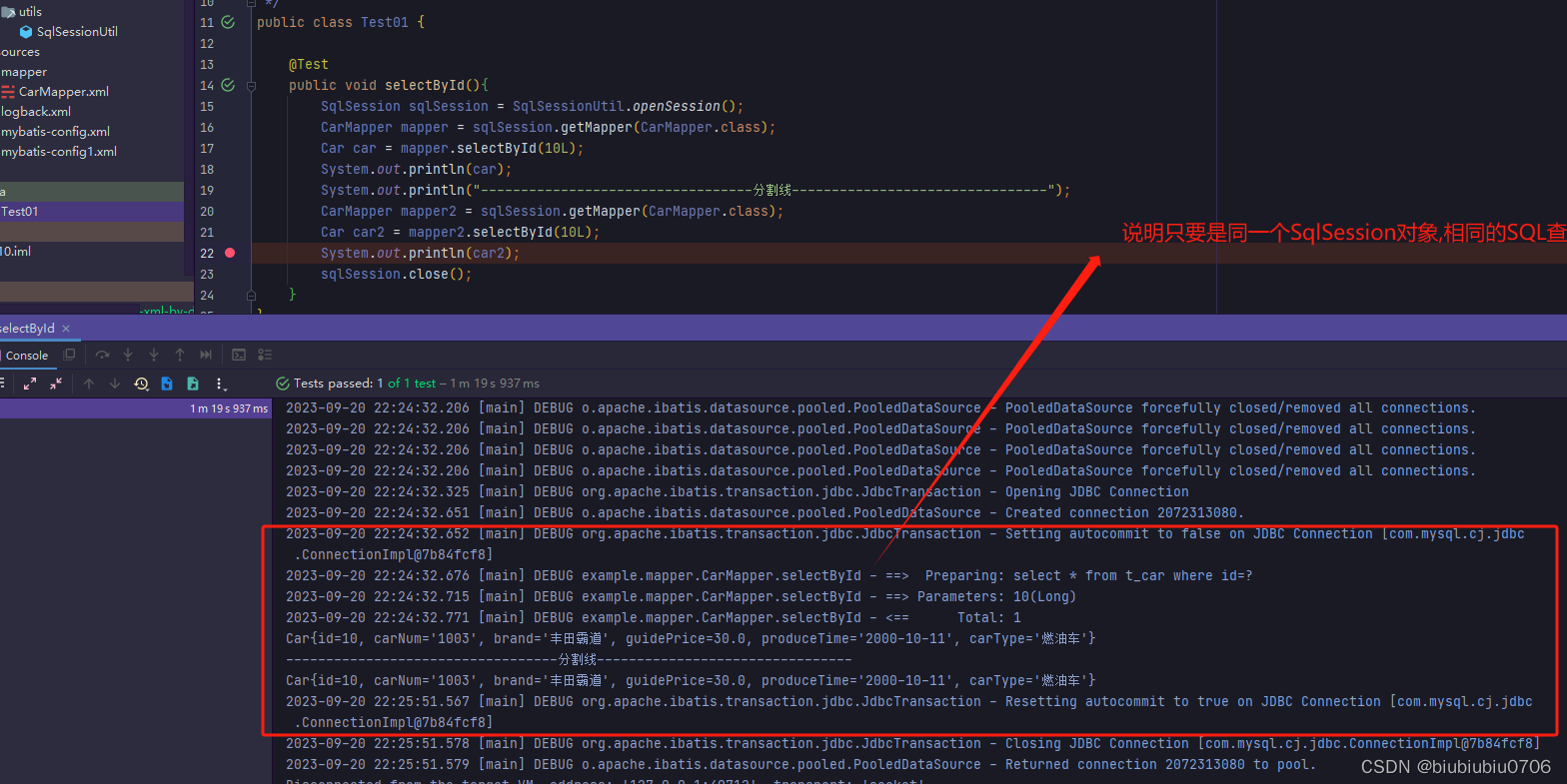
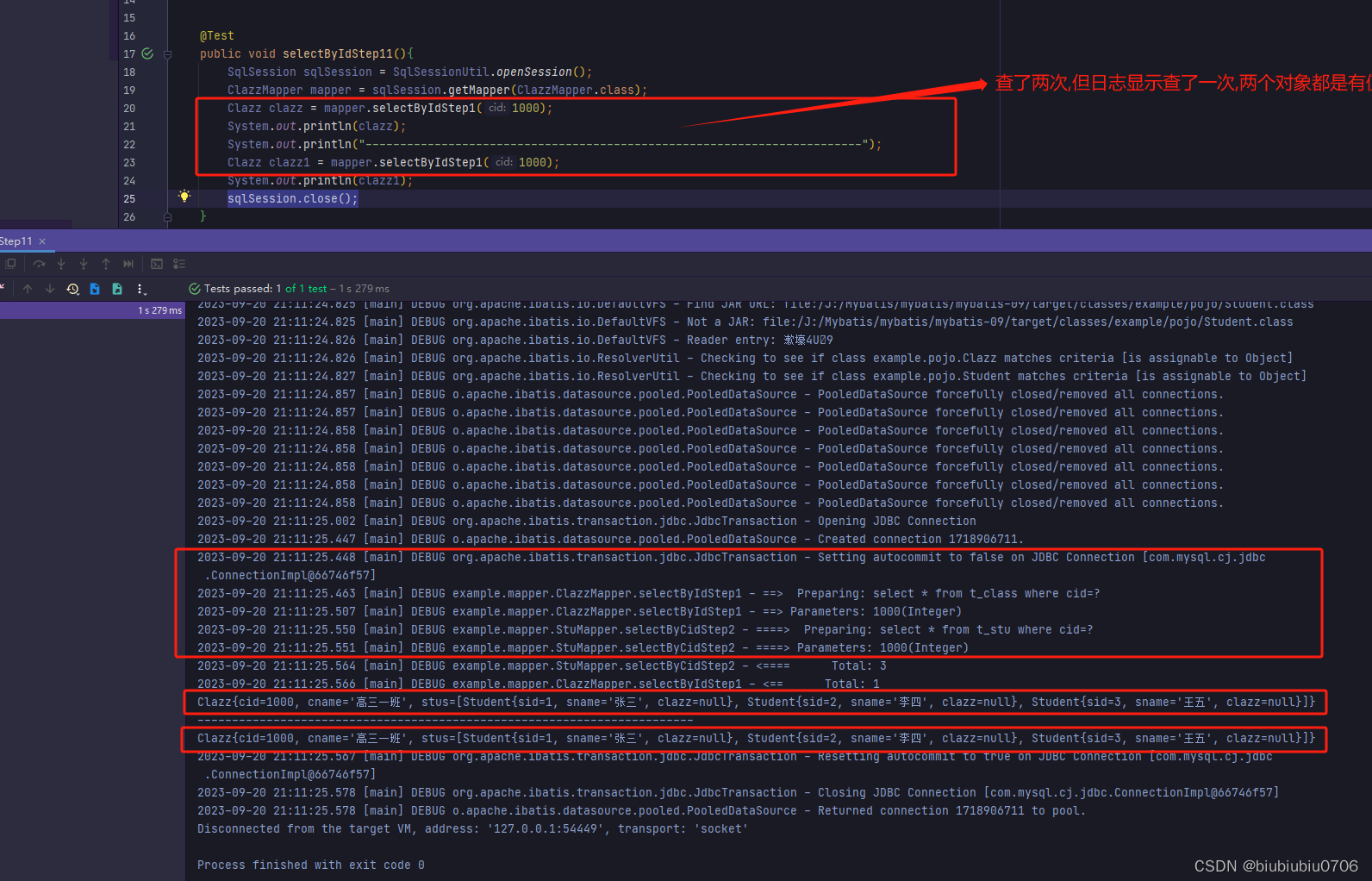
什么时候不走一级缓存
1.SqlSession对象不是同一个,因在SqlSessionUtil里用了ThreadLocal,所以演示sqlSession不一样,需要从SqlSessionFactory里取

2.查询条件不一样

什么时候一级缓存失效?
第一次DQL和第二次DQL之间做了以下两件事中的任意一件,都会让一级缓存清空.
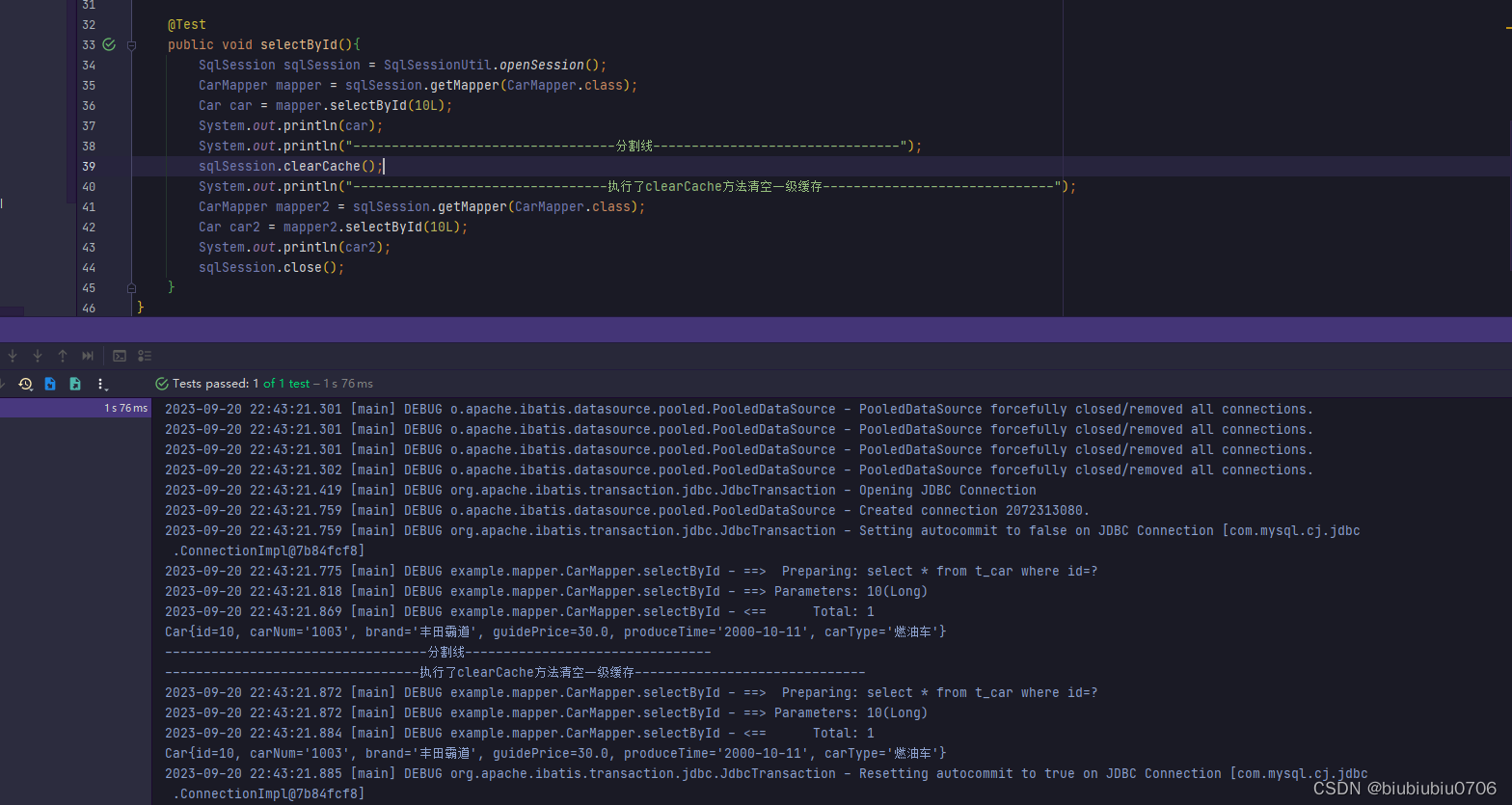
1.执行了sqlSession的clearCache()方法.这是手动清空缓存
2.执行了INSERT或DELETE或UPDATE语句.注意:不管你操作的是那张表.都会清空一级缓存
测试.clearCache()
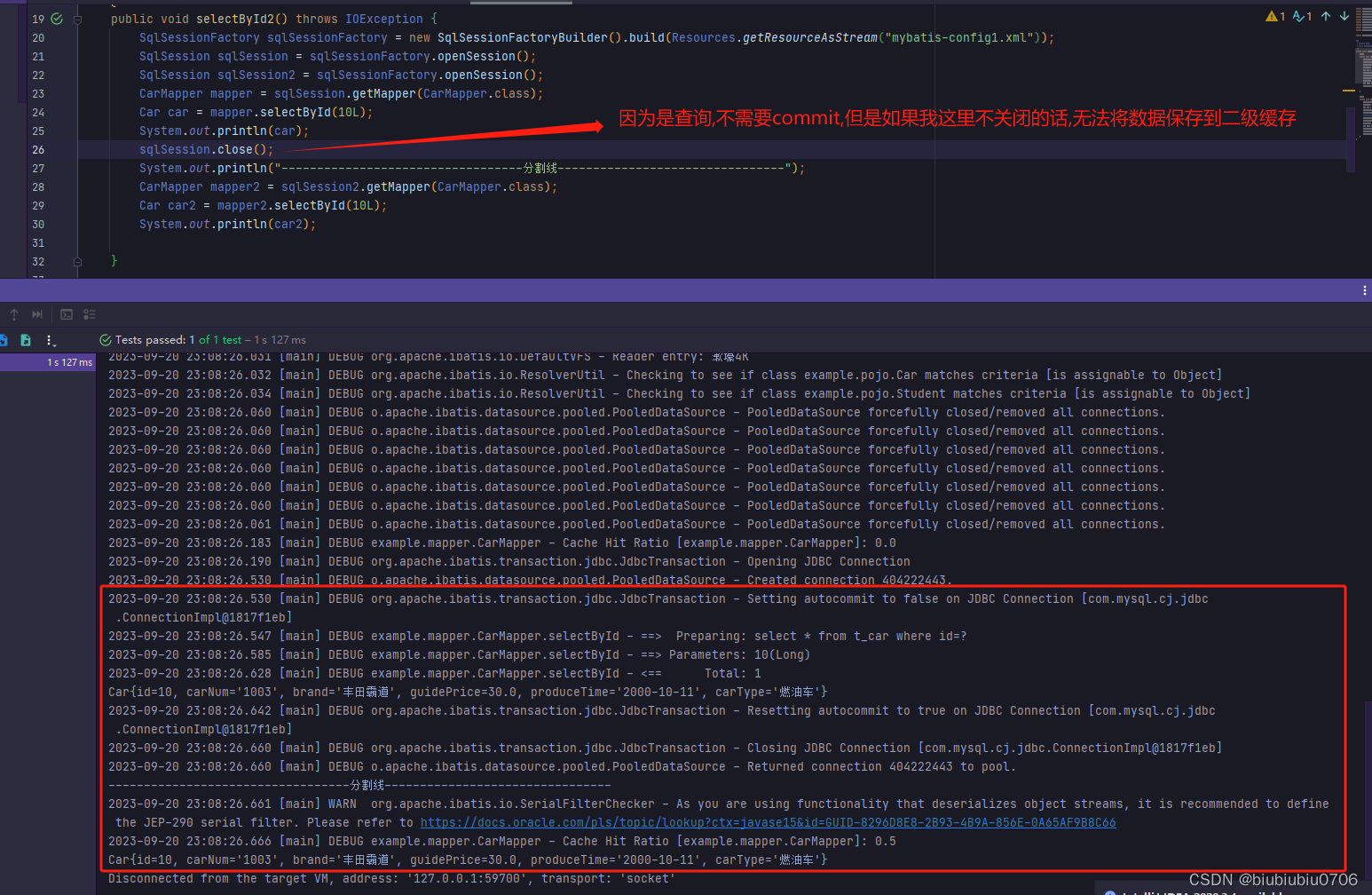
测试执行了任意表的增删改操作 这里忘记commit了 但即使没有commit缓存也清空了
注意:sqlSession.close()方法,只是关闭sqlSession,如果用了连接池,只是将sqlSession的状态更改为不可用,和commit没有关系,如果开启了事务,没有commit就不会提交
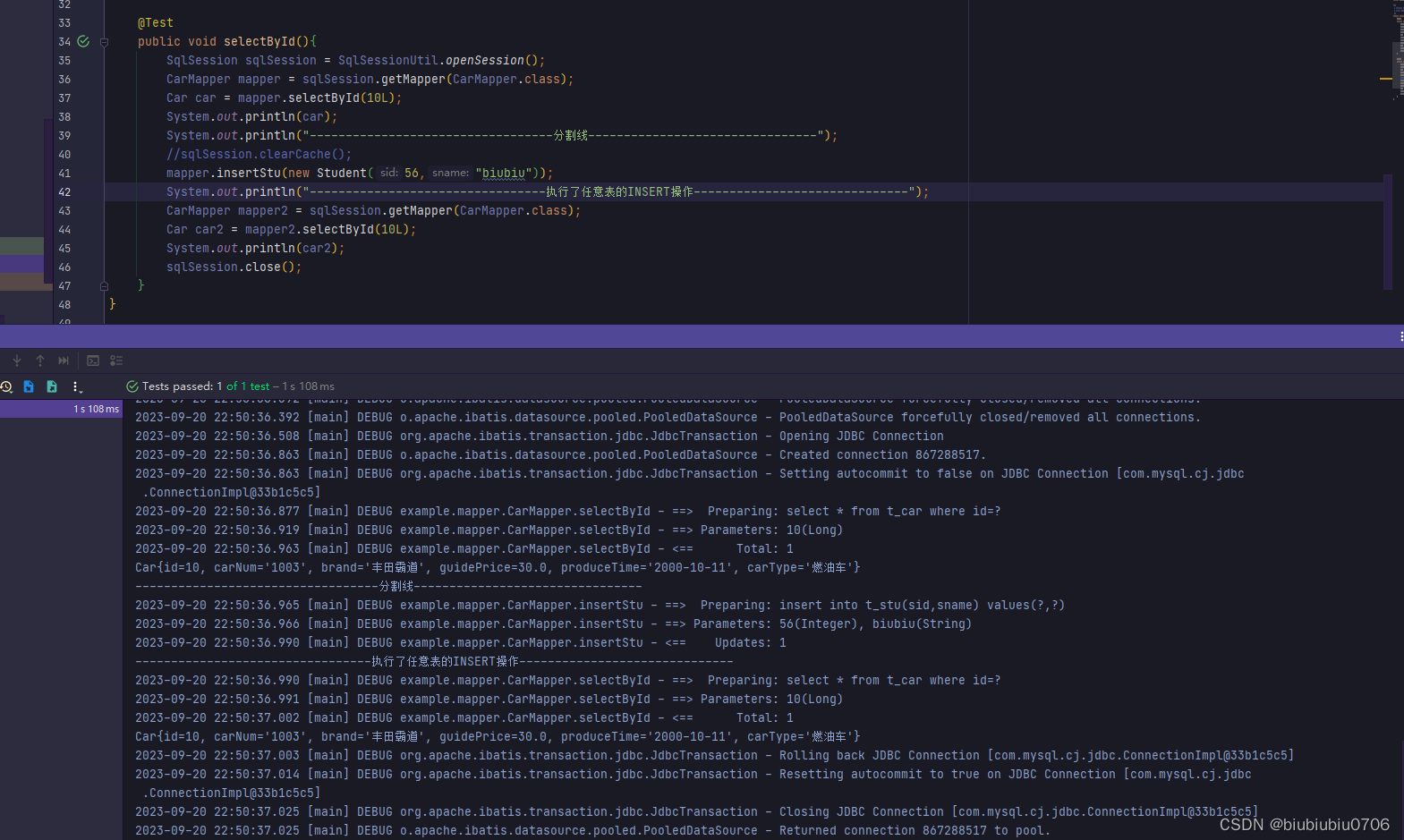
commit了

二级缓存
二级缓存的范围是SqlSessionFactory(应用运行期间)
使用二级缓存需要同时具备以下几个条件:
1.在Mybatis核心配置文件中配置<setting name="cacheEnabled" value="true">全局性的开启或关闭所有映射配置文件(XXX.xml)中已配置的任何缓存.默认就是true,一般无需设置.
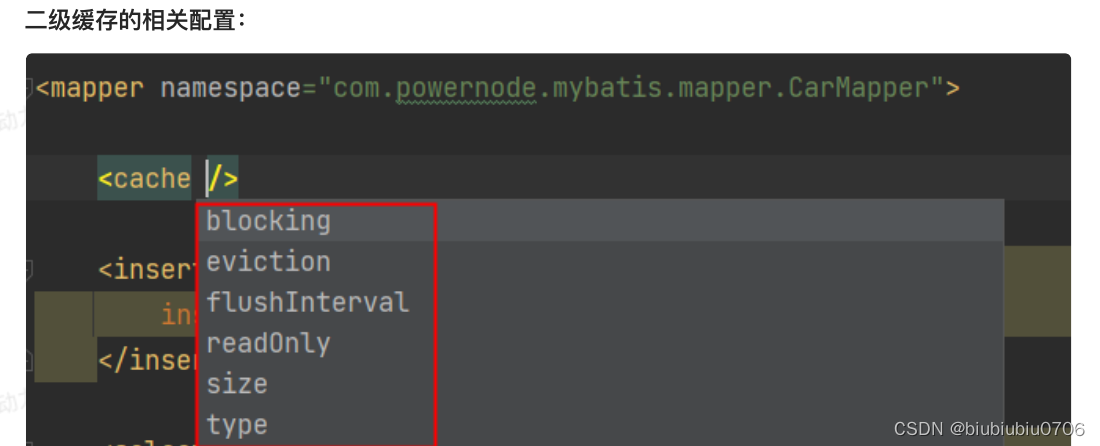
2.在需要使用二级缓存的XXX.xml映射文件中添加:<cache />
3.使用二级缓存的实体类对象必须是可序列化的,也就是必须实现java.io.Serializable接口
4.SqlSession对象关闭或提交之后,一级缓存中的数据才会被写入到二级缓存当中.此时二级缓存才可用.
要求1--->默认开启
要求2--->在需要使用二级缓存的XXX.xml映射文件中添加:<cache />

要求3--->实现序列化接口

要求4--->SqlSession对象关闭或提交之后,一级缓存中的数据才会被写入到二级缓存当中.此时二级缓存才可用.

如果这样的话都不会存到
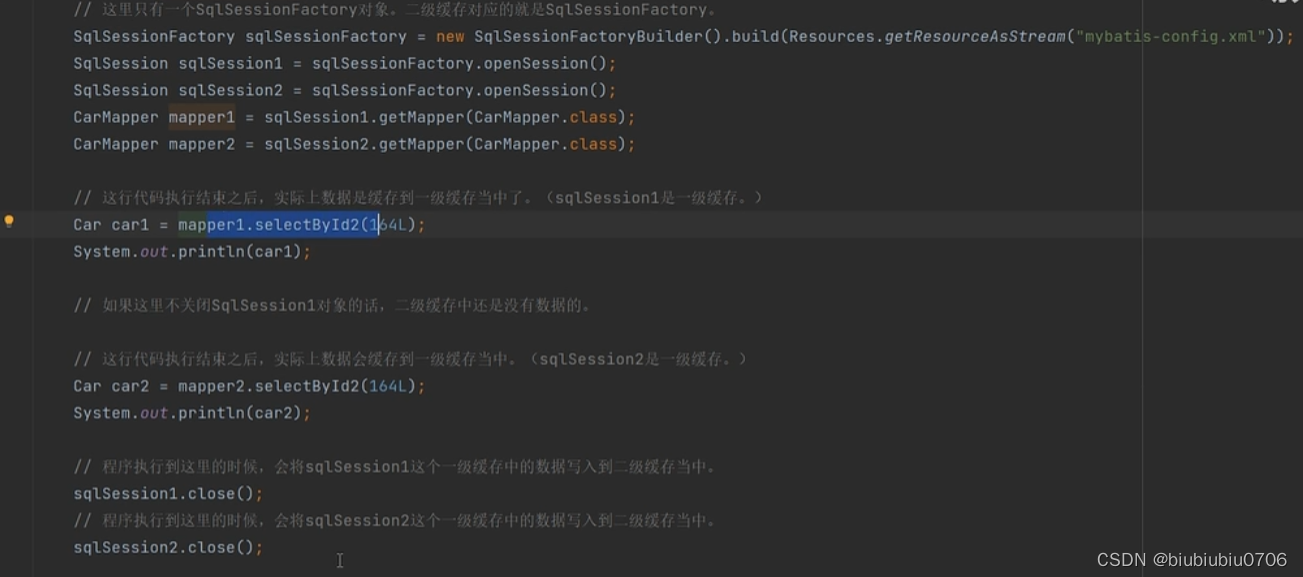

注意日志中的缓存命中率

二级缓存什么时候失效:只要两次查询之间出现了增删改操作,二级缓存就会失效.当然一级缓存也会失效
二级缓存相关配置




Mybatis集成EhCache
注意:集成EhCache是为了代替Mybatis得二级缓存,一级缓存无法替代.
也就是说集成EhCache是将原先保存在SqlSessionFactory中的缓存,放到第三方缓存插件中
Mybatis对外提供了接口.可以集成第三方缓存组件.比如EhCache,MemCache等
集成EhCache步骤:
1.引入依赖
<!--mybatis集成ehcache的组件--><dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.2.2</version></dependency><!--ehcache需要slf4j的⽇志组件,log4j不好使--><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.11</version><scope>test</scope></dependency>
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<!--磁盘存储:将缓存中暂时不使⽤的对象,转移到硬盘,类似于Windows系统的虚拟内存-->
<diskStore path="e:/ehcache"/>
<!--defaultCache:默认的管理策略-->
<!--eternal:设定缓存的elements是否永远不过期。如果为true,则缓存的数据始终有
效,如果为false那么还要根据timeToIdleSeconds,timeToLiveSeconds判断-->
<!--maxElementsInMemory:在内存中缓存的element的最⼤数⽬-->
<!--overflowToDisk:如果内存中数据超过内存限制,是否要缓存到磁盘上-->
<!--diskPersistent:是否在磁盘上持久化。指重启jvm后,数据是否有效。默认为false-->
<!--timeToIdleSeconds:对象空闲时间(单位:秒),指对象在多⻓时间没有被访问就会失
效。只对eternal为false的有效。默认值0,表示⼀直可以访问-->
<!--timeToLiveSeconds:对象存活时间(单位:秒),指对象从创建到失效所需要的时间。
只对eternal为false的有效。默认值0,表示⼀直可以访问-->
<!--memoryStoreEvictionPolicy:缓存的3 种清空策略-->
<!--FIFO:first in first out (先进先出)-->
<!--LFU:Less Frequently Used (最少使⽤).意思是⼀直以来最少被使⽤的。缓存的元
素有⼀个hit 属性,hit 值最⼩的将会被清出缓存-->
<!--LRU:Least Recently Used(最近最少使⽤). (ehcache 默认值).缓存的元素有⼀
个时间戳,当缓存容量满了,⽽⼜需要腾出地⽅来缓存新的元素的时候,那么现有缓存元素中时间戳
离当前时间最远的元素将被清出缓存-->
<defaultCache eternal="false" maxElementsInMemory="1000" overflowToDisk="false" diskPersistent="false"
timeToIdleSeconds="0" timeToLiveSeconds="600" memoryStoreEvictionPolicy="LRU"/>
</ehcache>
3.修改XXX.xml(映射文件)文件中的<cache />标签,添加type属性
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>