简介
"GPT-4,这是OpenAI在扩大深度学习方面的最新里程碑。GPT-4是一个大型的多模态模型(接受图像和文本输入,发出文本输出),虽然在许多现实世界的场景中能力不如人类,但在各种专业和学术基准上表现出人类水平的性能。" --OpenAI
GPT-4, 顾名思义是GPT-3和GPT-3.5的下一代模型。相比前面的模型,GPT-4多出了多模态的能力,简单来说,GPT-4除了具备理解输入的文本和生成文本的能力外,还具有了识别图像的能力,所以可以简单理解为GPT3.5 (ChatGPT初版背后的语言模型)具有了文本理解能力和说话的能力,而GPT-4在此基础之上拥有了视觉,并增强了自己的语言理解能力。
GPT-4刚出来的时候,虽有很多人大喊🐂🍺, 但也有不少人会有点失望。当然失望不是模型不够强,而是因为等待时间比较久且期待比较高。GPT-4的相关详细远在去年的时候就已经被放出,根据OpenAI官方公布的技术报告, GPT-4模型在去年的8月就已经完成训练,之后一直在测试它的安全性和可靠性。在gpt-4出来之前,已知GPT-3模型拥有1750亿的参数,而GPT-4的参数会达到万亿级别,再加上去年AIGC带来的热度,尤其是文本生成图像和视频,大家猜测GPT-4会拥有图像生成能力。在GPT-4正式发布前夕,微软公布了两篇多模态模型(具备本文生成和图像生成能力)的论文,德国的CTO也说GPT-4能够处理视频,于是大家对GPT-4的期望被拉到了一个很高的地步——能够把图像、文本、语音、视频全部能做的巨无霸。但是最后公布后,它只能接受图像和文本的输入,并只能输出文本。
言归正传, GPT-4相比GPT-3在文本的能力上还是有很大的提升,除了日常对话之外,它的考试能力和写代码能力都有很大的提升。其中一个GPT-4发布时的一个名场面就是OpenAI的联合创始人 Greg Brockman在一张纸上手绘了一个网页端的界面,然后把图片上传给模型,GPT-4根据它画出的UI界面生成了可运行的代码。 在考试方面,GPT-4不仅仅通过了律师资格考试,而且在考生中排名前10%,而GPT-3.5在这个考试中只能排末尾的10%。
Open AI为了训练GPT-4专门部署了计算集群能够更高效准确稳定地训练大语言模型。其中一个很重要的特性就是他们的框架能够准确预测出模型的性能,在AI的研究中,由于大模型规模非常大,模型参数很多,在大模型上跑完来验证参数好不好训练时间成本很高,所以一般会在小模型上做消融实验来验证哪些改进是有效的再去大模型上做实验。然而在语言模型上,因为模型太大了,一些在小模型上有效果的改进在大模型上是无效的,还有大模型特有的涌现能力无法在小模型上体现。而openai的这个系统在小规模成本的训练下能够精准预测到扩大训练规模的模型性能,这个能够有效地解决上述问题。
训练
在预训练过程中,GPT-4的训练数据包含了大量网络上爬下来的数据,包括了很多有正解和错误解的数学问题、强推理、弱推理、自相矛盾的,保持一致的陈述、各种各样的意识形态和想法的文本。
预训练好的模型有些是在错误的答案上训练过的,所以刚训练好的模型有些回答并不是我们想要的,为了和人类的意图保持一致并且回答安全可控,使用了基于人类反馈的强化学习(RLHF)来对模型进行微调来教模型如何理解人类的输入和生成对应的输出。
虽然有微调的过程,但是OpenAI的论文指出,RLHF并不能提高模型在考试上的表现,如果调参不妥当甚至还会降低它的能力,因此可以推断出模型强大的文本能力是靠巨量数据、大算例堆起来(力大飞砖)。 而人类的干预是去引导、控制它来正确展示自己的能力,用人类喜欢的方式来回答人类的问题。
预测scaling
前面提到过OpenAI为了稳定地训练大语言模型专门建立了训练模型的集群,并且有专门的优化方法能够在不同尺度的实验上可以稳定地预测。OpenAI的团队在GPT-4开始训练的时候就已经能预测GPT-4最终完成的loss,具体来说他们在使用一个小一万倍的模型上训练出来的Loss,并且推出GPT-4的Loss,最终证实了预测与实际的Loss是拟合的。
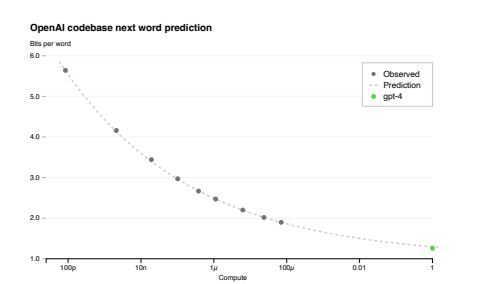
上面这张图,纵坐标可以看成是loss的指标,横坐标是计算的规模,绿色的点是GPT-4最终训练完成后的loss,而灰色的点是不同尺度下训练的模型的loss,可以看出用小模型训练出的loss延伸出去后与实际GPT-4训练完成的Loss是拟合的。因此他们可以用更快的速度尝试更多的方法,做大量的实验。
除此之外,在集群上训练大模型会遇到非常多的问题,比如训练的loss跑飞,断网,设备中断等,而OpenAI的基础设施为能够让训练非常的稳定,除了钞能力外还需要团队有非常强大的工程能力。
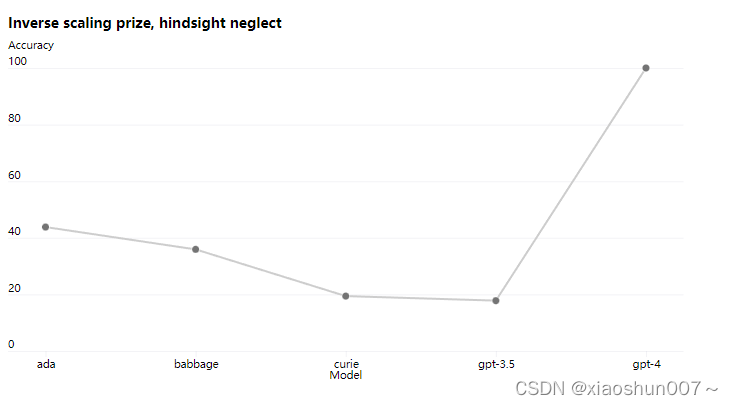
然而目前并不是所有能力都能预测,比如inverse scaling prize的一个专门给大模型找茬的比赛。GPT-3出现后很多人认为模型越大效果越好,而一部分的研究者认为不一定,于是去寻找一些模型越大,效果越差的一些任务,于是便诞生了这个比赛。其中一个叫hindsight neglect的任务,简单来说这个任务就是:过去你做一件事的时候很理性的判断做了一个决策,这个决策按道理来说是正确的,可惜运气不好,最后这个决策的结果不是很好,于是再问你如果能回到过去,你会继续做这个理性的决策还是选择更冒险的决策?
理想情况下,我们应该每一次都做理性的决策是最理想的,然而之前模型越大反而越不理智。GPT-3之前的模型,随着模型越大准确率越低,而到了GPT-4则开始反过来,GPT-4的准确率已经接近100%,于是可以推测可能GPT-4已经拥有了一定的推理能力。