目录
1)下载时间同步工具,并配置时间源,实现slave库与master库时间同步
3、在master数据库服务器和slave数据库服务器上给amoeba开放权限
4、在amoeba服务器上修改amoeba的客户端配置文件amoeba.xml
MySQL主从复制
1、mysql支持的复制类型
(1)STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高。
(2)ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
(3)MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
2、主从复制的工作过程
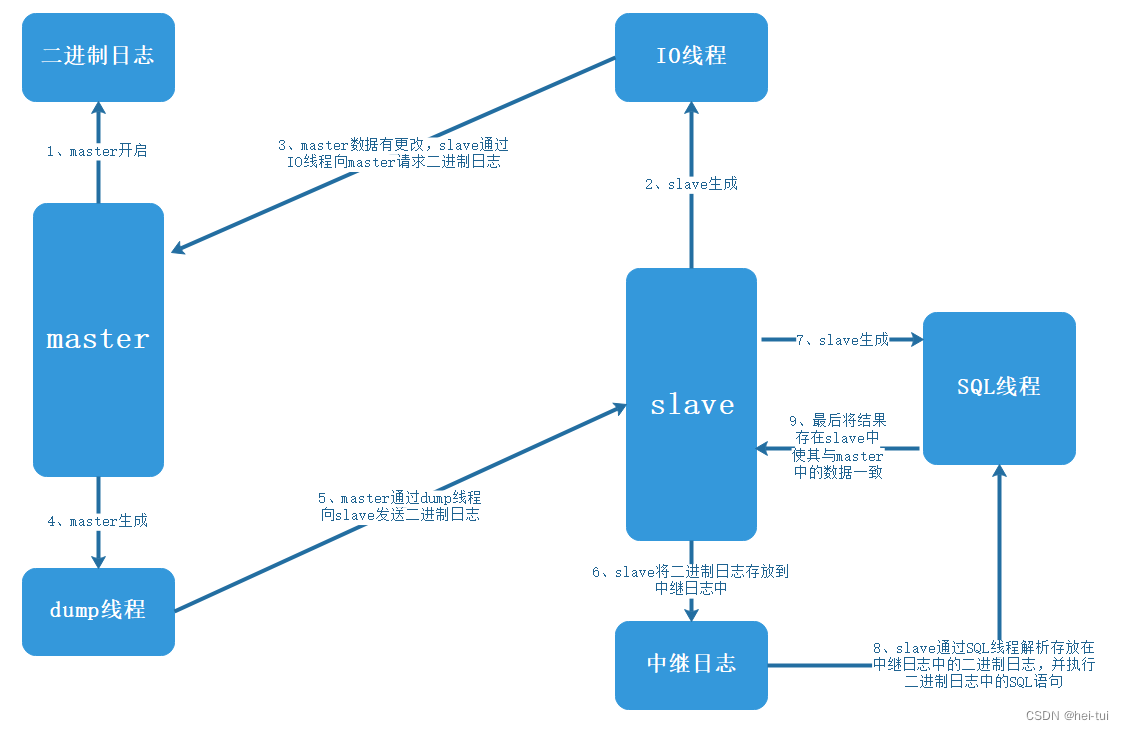
1)master库在配置文件/etc/my.cnf中开启二进制日志功能,master库中的数据发生改变时,将记录在二进制日志文件中;
2)slave库在检测master库中是否有更改,有更改的话,发送一个I/O 线程请求二进制日志文件;
3)master库在收到slave库的I/O 线程请求,master库使用dump线程给slave库发送自己的二进制日志文件;
4)slave库在收到master库发送来的二进制日志文件后,将其存放到自己的中继日志(relay log)中,并启用SQL线程解析中继日志中二进制日志的内容,解析成SQL语句,并一一执行,使slave库中数据与master库中的数据保持一致。
3、主从复制操作
环境:
主(master)数据库:192.168.3.10
从(slave1)数据库:192.168.3.11
从(slave2)数据库:192.168.3.12
1)下载时间同步工具,并配置时间源,实现slave库与master库时间同步
master库
yum install -y ntp #下载时间同步工具
vim /etc/ntp.conf
21 #server 0.centos.pool.ntp.org iburst #注释掉
22 #server 1.centos.pool.ntp.org iburst #注释掉
23 #server 2.centos.pool.ntp.org iburst #注释掉
24 #server 3.centos.pool.ntp.org iburst #注释掉
25 server 127.127.3.0 #添加本地时间源
26 fudge 127.127.3.0 stratum 8 #设置时间层级
systemctl start ntpd
systemctl status ntpd



slave库
yum install -y ntp #下载时间同步工具
vim /etc/ntp.conf
21 #server 0.centos.pool.ntp.org iburst #注释掉
22 #server 1.centos.pool.ntp.org iburst #注释掉
23 #server 2.centos.pool.ntp.org iburst #注释掉
24 #server 3.centos.pool.ntp.org iburst #注释掉
25 server 192.168.3.10 #同步master库中的时间
systemctl start ntpd
systemctl status ntpd



2)、配置主master库
修改mysql配置文件
vim /etc/my.cnf
server-id = 1
log-bin=mysql-bin
binlog_format=mixed
systemctl restart mysqld.service

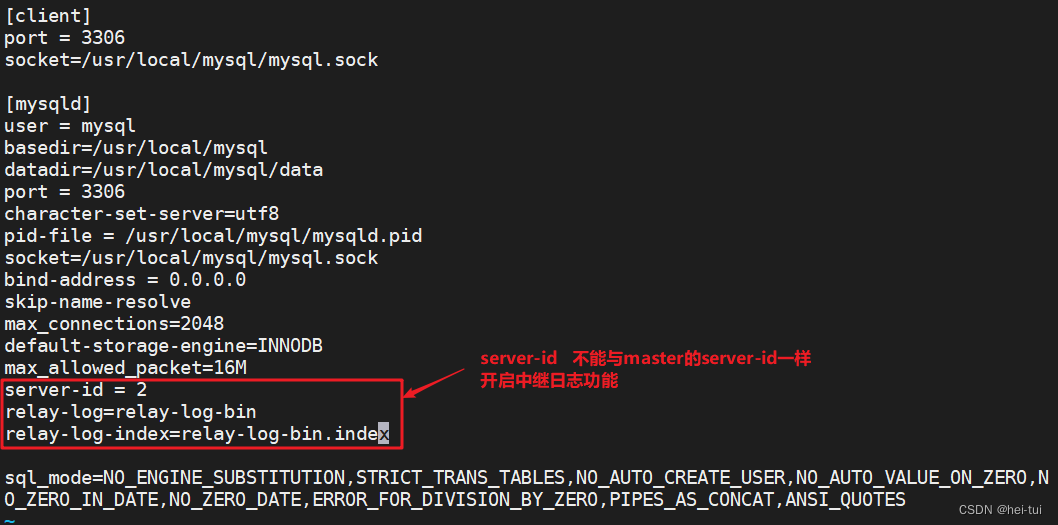
3)配置slave库
修改mysql配置文件
vim /etc/my.cnf
server-id = 1
log-bin=mysql-bin
binlog_format=mixed
systemctl restart mysqld.service
4)登录主MySQL,给从服务器授权
mysql -u root -p123123
grant replication slave on *.* to 'myslave'@'192.168.3.%' identified by '123123';flush privileges; #刷新权限,立即生效

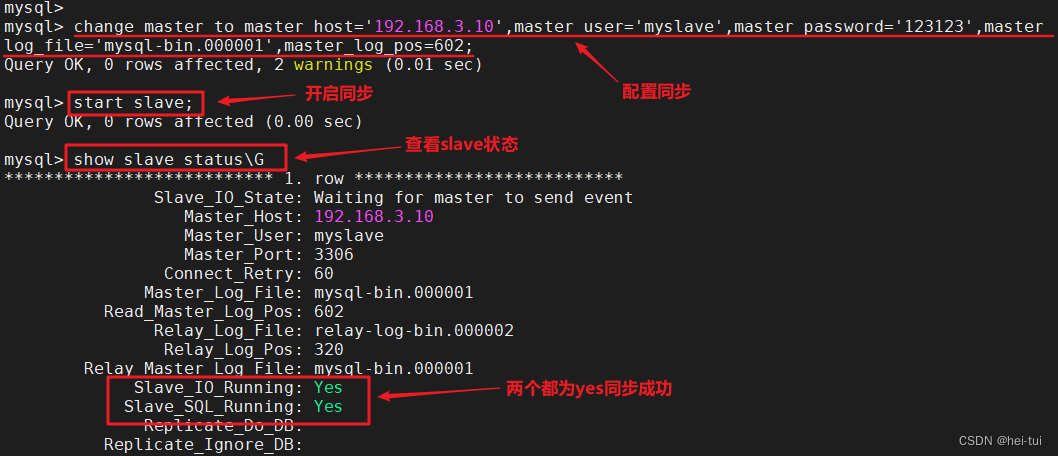
5)登录从数据库,配置同步,并启动同步
mysql -uroot -p123123
change master to master_host='192.168.3.10',master_user='myslave',master_password='123123',
master_log_file='mysql-bin.000001',master_log_pos=602;
start slave; #开启同步
show slave status\G #查看slave状态
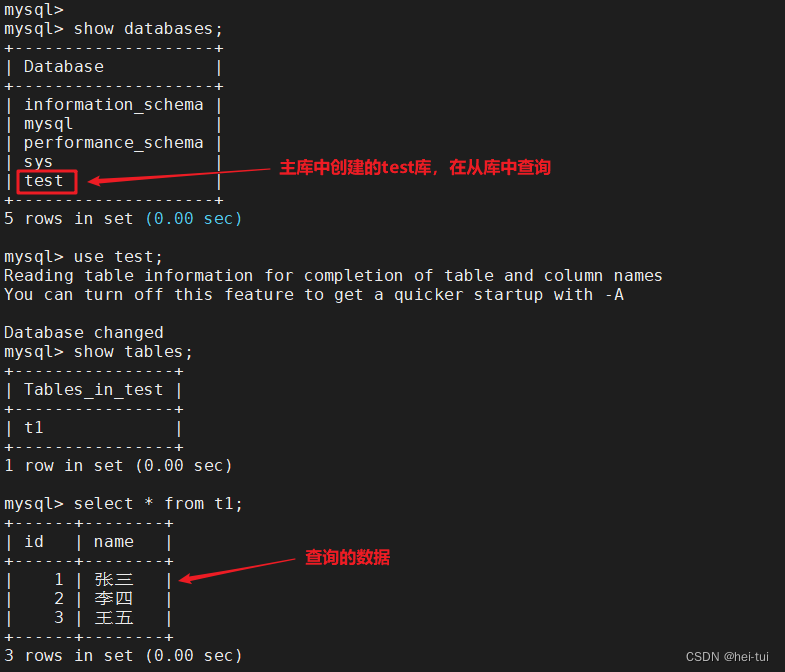
6)测试
在主库中创建创建库,创建表,添加数据,在从库中查看
主库:
create database test;
use test;
create table t1(id int, name char(10));
insert into t1 values(1,'张三');
insert into t1 values(2,'李四');
insert into t1 values(3,'王五');

从库:
show databases;
use test;
show tables;
select * from t1;
MySQL读写分离
MySQL读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
目前较为常见的MySQL读写分离
1、基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。
优点:性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;
缺点:需要开发人员来实现,运维人员无从下手。
但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的Java应用,如果在程序代码中实现读写分离对代码改动就较大。
2、基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有以下代表性程序。
(1)MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
(2)Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
(4)Mycat。是一款流行的基于Java语言编写的数据库中间件,是一个实现了MySql协议的服务器,其核心功能是分库分表。配合数据库的主从模式还可以实现读写分离。
我们运维人员仅需要管理基于中间代理层实现的读写分离
基于中间代理层的读写分离操作
使用Amoeba工具为例:
环境:读写分离基于上方的主从复制继续操作的
Amoeba中间代理服务器:192.168.3.106
master数据库:192.168.3.10
slave1数据库:192.168.3.11
slave2数据库:192.168.3.12
客户机:192.168.3.105
1、安装java环境
导入jdk安装包
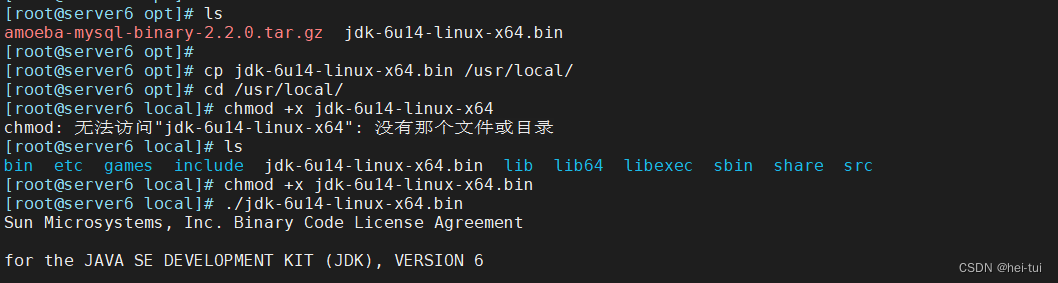
cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/ 将jdk安装包拷贝到/usr/local下
cd /usr/local/
chmod +x jdk-6u14-linux-x64 #给jdk安装包加上执行权限
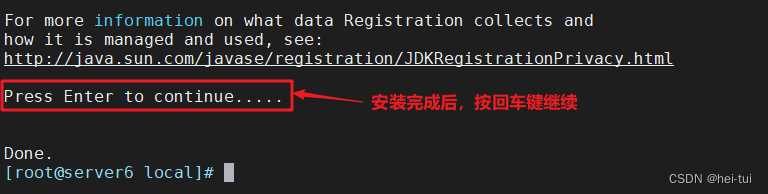
./jdk-6u14-linux-x64.bin #安装jdk//按yes,按enter
mv jdk1.6.0_14/ /usr/local/jdk1.6 #改名
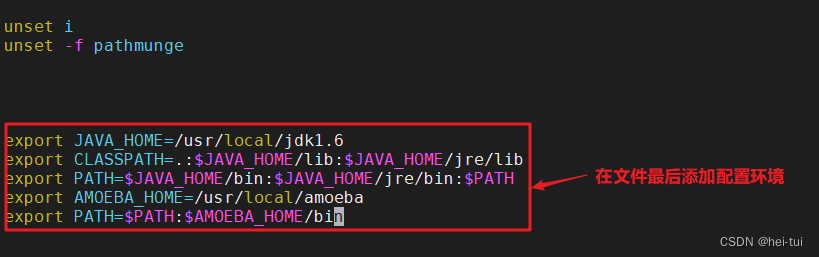
vim /etc/profile #配置环境变量
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile #刷新环境变量文件java -version #查看java版本



2、安装Amoeba
导入Amoeba安装包
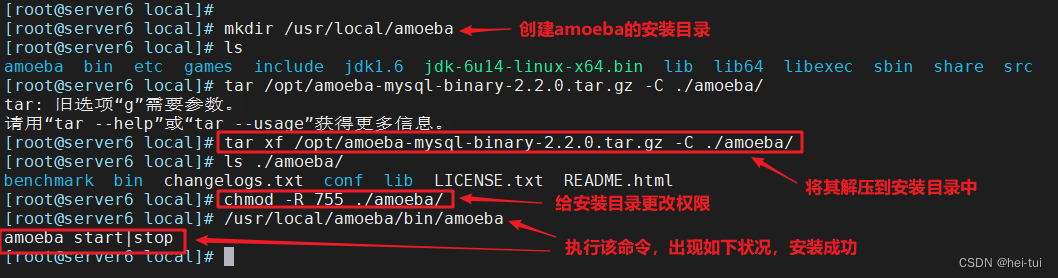
mkdir /usr/local/amoeba
tar xf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
//如显示amoeba start|stop说明安装成功
3、在master数据库服务器和slave数据库服务器上给amoeba开放权限
grant all on *.* to test@'192.168.3.%' identified by '123123';

4、在amoeba服务器上修改amoeba的客户端配置文件amoeba.xml
cd /usr/local/amoeba/conf/
cp amoeba.xml amoeba.xml.bak
vim amoeba.xml #修改amoeba配置文件
--30行--
<property name="user">amoeba</property> #设置客户端登录的用户
--32行--
<property name="password">123456</property> #设置客户端登录的密码
--115行--
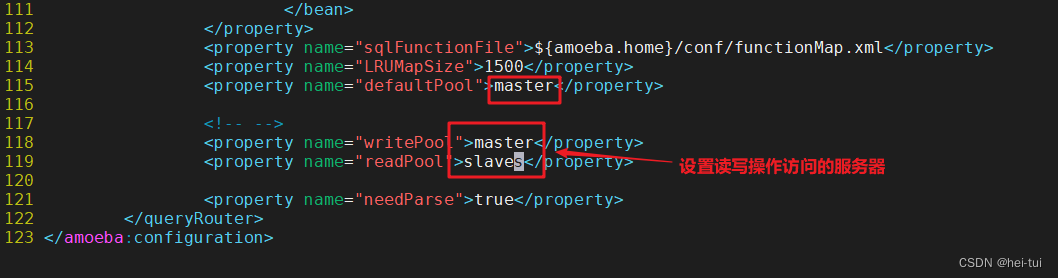
<property name="defaultPool">master</property> #默认master数据库服务器
--117-去掉注释-
<property name="writePool">master</property> #写操作,访问master数据库服务器
<property name="readPool">slaves</property> #读操作,访问slaves池中的slave数据库服务器

5、修改amoeba与数据库连接的配置文件
cp dbServers.xml dbServers.xml.bak #备份
vim dbServers.xml #修改数据库配置文件
--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
--26--修改
<property name="user">test</property> #设置为数据库服务器给amoeba服务器授权的用户
--28-30--去掉注释
<property name="password">123123</property> #设置为数据库服务器给amoeba服务器授权的用户登录密码
--45--修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址
<property name="ipAddress">192.168.3.10</property>
--52--修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址
<property name="ipAddress">192.168.3.11</property>
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.3.12</property>
--65行--修改
<dbServer name="slaves" virtual="true">
--71行--修改
<property name="poolNames">slave1,slave2</property>


6、启动amoeba服务
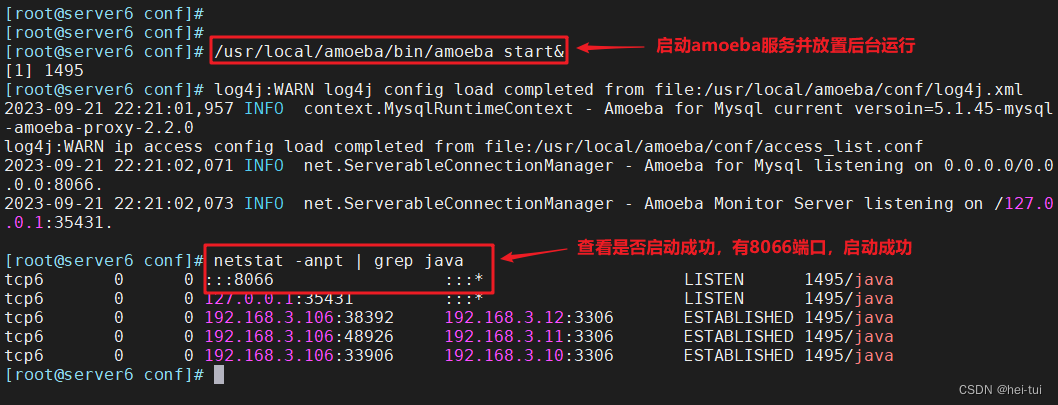
/usr/local/amoeba/bin/amoeba start& #放入后台启动
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 8066
7、使用客户机测试
客户机上需要安装数据库,不管是mysql还是mariadb都可以
mysql -uamoeba -p123123 -h 192.168.3.106 -P8066 登录

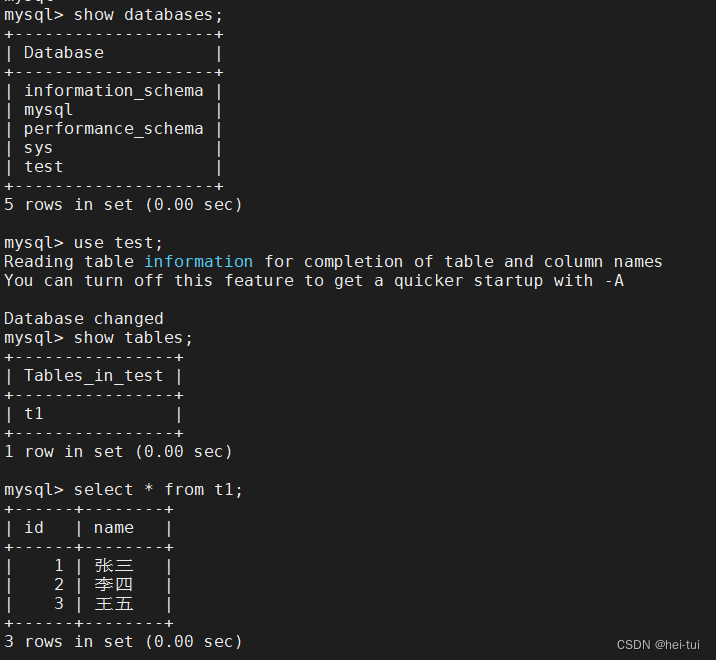
在主数据库上创建数据库和数据表
create database test;
use test;
create table t1(id int, name char(10));
insert into t1 values(1,'张三');
insert into t1 values(2,'李四');
insert into t1 values(3,'王五');
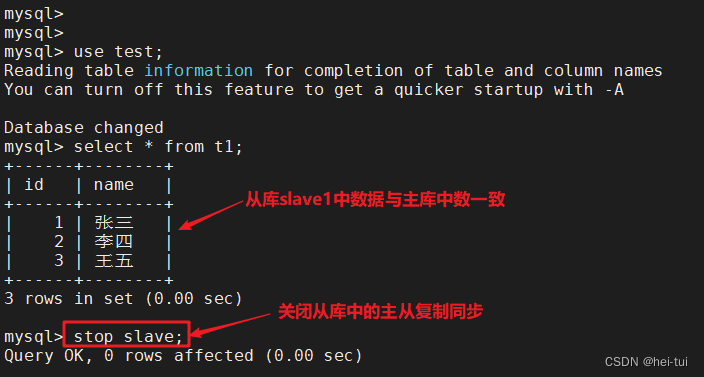
两个从表都关闭同步
stop slave;
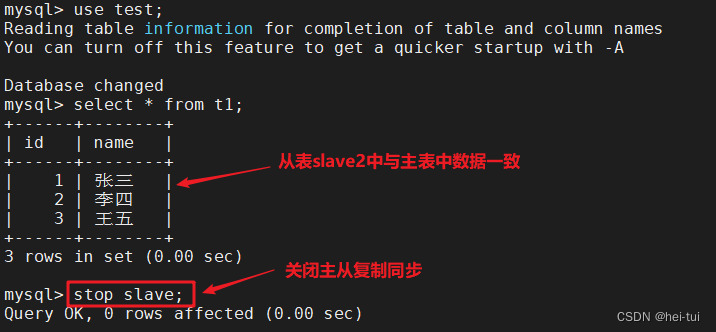
分别在从库slave1和slave2中对t1表插入不一样的数据
slave1:
insert into t1 values(4,'赵六');
insert into t1 values(5,'孙七');
slave2:insert into t1 values(6,'周八');
insert into t1 values(7,'吴九');

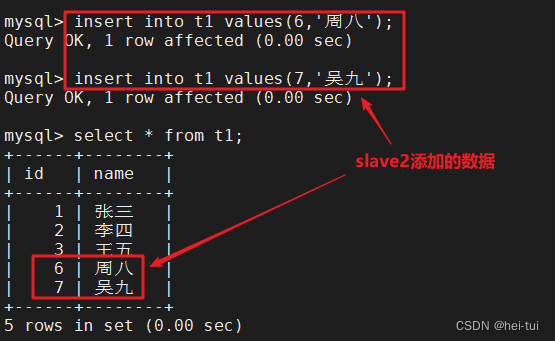
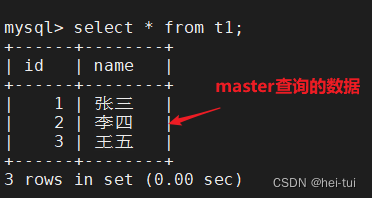
使用master查询t1表的数据
select * from t1;
使用客户机连续4次查询的结果
select * from t1;
select * from t1;
select * from t1;
select * from t1;

在客户端向t1表插入数据
insert into t1 values (8,'郑十');
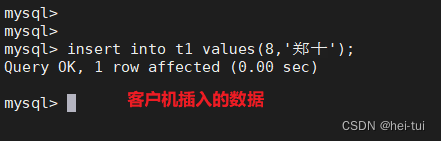
分别使用master服务器和slave1和slave2服务器查询t1表,查看客户机插入的数据在哪一台服务器上实现的
select * from t1;

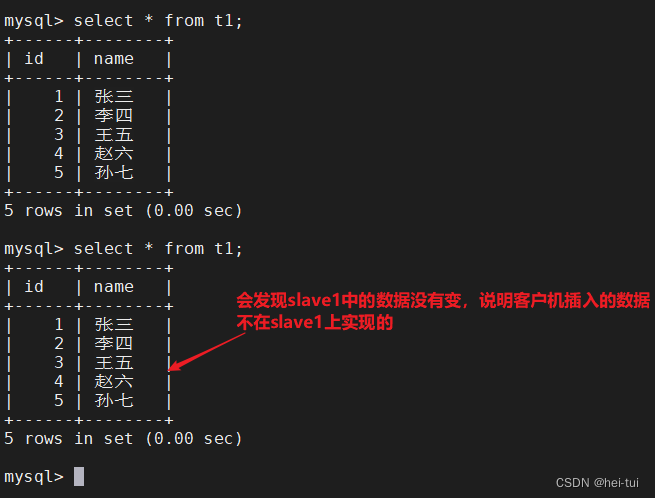
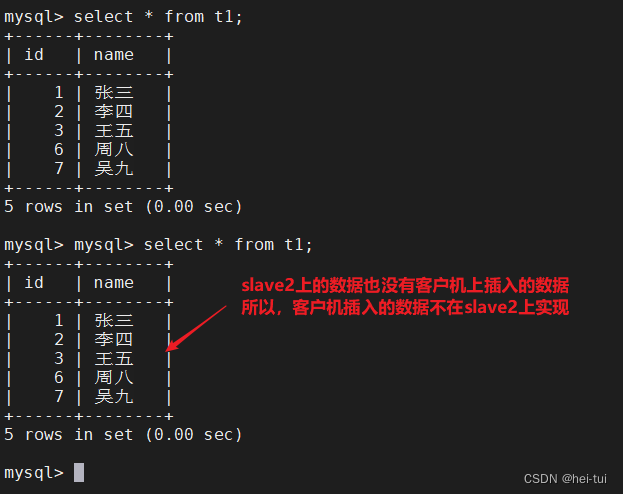
从上诉结果可以看到,读操作实在slave1和slave2服务器上实现的,而写操作实在master服务器上实现的,所以实现了mysql的读写分离操作。








