若该文为原创文章,转载请注明原文出处。
一、DeepSORT简介
DeepSORT 是一种计算机视觉跟踪算法,用于在为每个对象分配 ID 的同时跟踪对象。DeepSORT 是 SORT(简单在线实时跟踪)算法的扩展。DeepSORT 将深度学习引入到 SORT 算法中,通过添加外观描述符来减少身份切换,从而提高跟踪效率。
这是提供两个demo,一是跟踪计数人员;二是车辆计数跟踪;
二、环境搭建
本人没有GPU的电脑,所以修改一些参数在CPU上跑,只是为了学习验证。
1、创建虚拟环境
conda create -n yolov5_deepsort_env python==3.82、激活环境
conda activate yolov5_deepsort_env3、下载代码
链接:https://pan.baidu.com/s/1CSfqIrDh-r17wDvm_rOF-A?pwd=1234
提取码:1234 
4、安装yolov5
进入存放的路径,修改成自己的路径:
cd G:\enpei_Project_Code\02_deepsort\yolov5-deepsort安装
pip install -r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple安装成功:

接下来验证
三、测试
执行
python .\count_car.py结果报错了

所以下面处理各种错误:
错误1:ImportError: cannot import name 'EasyDict' from 'easydict' (unknown location)
原因是easydict版本不对,需要指定版本。
处理:下载easydict,并重新安装;
下载地址:
下载后解压,并安装,安装指令如下:
python setup.py install --user
错误2:RuntimeError: "slow_conv2d_cpu" not implemented for 'Half'
原因:因为没有Cuda支持,无法使用半精度VAE模块进行推理
处理:找到文件下的half,全部修改成float

错误3:AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
处理:
打开D:\Anaconda3\envs\yolov5-6.0\lib\site-packages\torch\nn\modules\upsampling.py(注意路径,为环境下)
修改代码
def forward(self, input: Tensor) -> Tensor:
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
# return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners,
# recompute_scale_factor=self.recompute_scale_factor)
错误4:AttributeError: module 'numpy' has no attribute 'float'.
原因:numpy版本不对,重新安装numpy
处理:
pip uninstall numpy
pip install numpy==1.20.3
所有错误处理完后,在次运行
python .\count_car.py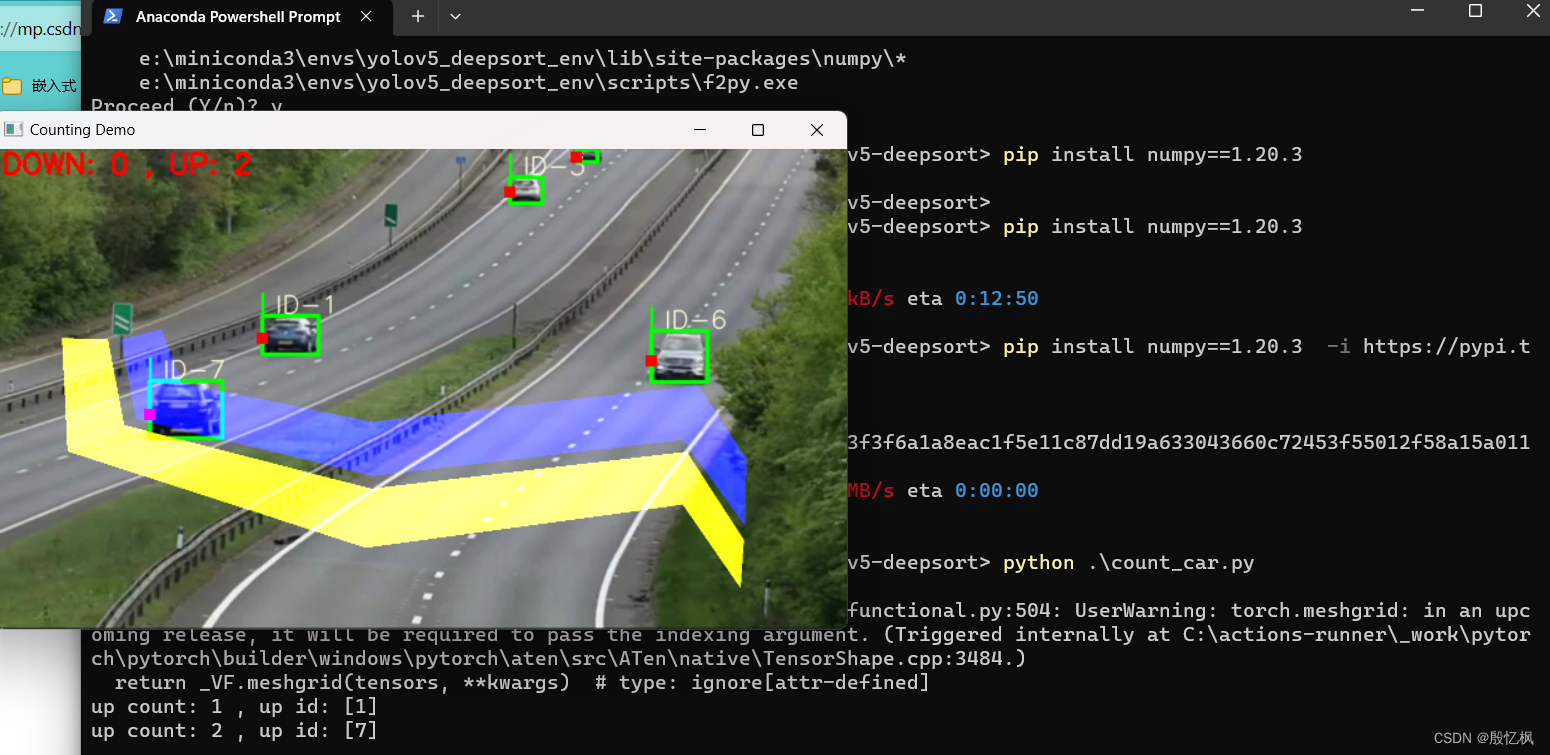
代码比较易懂,值得学习,这里不过不解析代码。
如有侵权,或需要完整代码,请及时联系博主。










