目录:
1. 基本查询
2. 条件查询(where)
3. 聚合函数(count、max、min、avg、sum)
4. 分组查询(group by)
5. 分组后查询(having)
6. 排序查询(order by)
7. 分页查询(limit)
1. 基本语法
SELECT
字段
FROM
表名
WHERE
条件
GROUP BY
分组
HAVING
分组后条件
ORDER BY
排序
LIMIT分页参数
1.1. 查询多个字段
select 字段1,字段2,...from 表名;
1.2. 查询所有字段
select * from 表名;
1.3. 给字段设置别名
select 字段1 别名1, 字段2 别名2,... from 表名;
1.4. 去除重复记录
select distinct 字段 from 表名;
2. 条件查询(where)
SELECT * FROM 表名 WHERE 条件
| 比较运算符 | 功能 | 逻辑运算符 | 功能 |
| > | 大于 | AND或&& | 并且(多个条件需同时成立) |
| >= | 大于等于 | OR或 || | 或者(某个条件成立即可) |
| < | 小于 | NOT 或 ! | 非,取反 |
| <= | 小于等于 | ||
| = | 等于 | ||
| <>或!= | 不等于 | ||
| BETWEEN...AND... | 在某个范围之内(最小值、最大值) | ||
| IN(...) | 包含 | ||
| LIKE 占位符 | 模糊查询(_匹配单个字符,%匹配多个字符) | ||
| is NULL | 是NULL | ||
| ="" | 等于空 |
2.1 下面这几个简单的就不演示了
select * from 表名 where 字段 > 值; -- 大于
select * from 表名 where 字段 >= 值; -- 大于等于
select * from 表名 where 字段 < 值; -- 小于
select * from 表名 where 字段 <= 值; -- 小于等于
select * from 表名 where 字段 = 值; -- 等于
select * from 表名 where 字段 <> 值 或 select * from 表名 where 字段 != 值; -- 不等于
2.2 在某个范围之内:BETWEEN...AND...

如上学生表,假如让你查询成绩在80以上,90以下,你可以这样
select * from students where 成绩 >= 80 and 成绩 <= 90;
但是这样查有时候过于繁琐,如果查询的是一个范围, 且有最小值和最大值,你可用BETWEEN...AND...,如下
select * from students where 成绩 between 80 and 90;
2.3 IN(...) 包含
查询包含(张三)和(李四)的记录
select * from students where 姓名 in ('张三','李四');
2.4 LIKE 模糊查询
查询性张的学生记录。_一个下划线的意思就是"张"后面只允许出现一个字,两个下划线允许出现两个字,而%号允许出现任何数字
select * from students where 姓名 like ('张_');
select * from students where 姓名 like ('张%');
2.5 is NULL 和 = "" (是NULL,等于空)
要注意这两个不是同一个东西,一般来说is null 是用于数字查询上, = "" 是用于字符串查询上,NULL和空的区别是,null是未知值;而空是已知值,值就是空

select * from students where 成绩 is null; -- 查询成绩为null的记录
select * from students where 姓名 = ''; -- 查询姓名为空的记录
2.6 AND或&& (并且)
查询姓名为(张三)并且年龄等于(20)的记录
select * from students where 姓名 = '张三' and 年龄 = 20;
select * from students where 姓名 = '张三' && 年龄 = 20;
2.7 OR或 || (或者)
查询姓名为(张三)或者年龄等于(21)的记录
select * from students where 姓名 = '张三' or 年龄 = 20;
2.8 NOT 或 !(非、取反)
首先说一下<> != 和 not ! 的区别, <> != 用于比较两个值不相等的情况, 而not !是对于结果取反,其实他们的用意都是一样的, 只是写法不一样。
查询姓名等于(张三)的反记录
select * from students s where not 姓名 = '张三';
3. 聚合函数
聚合函数是将一列作为一个查询整体进行纵向计算的。通俗来说就是聚合函数通常是用来计算列的
| 函数 | 功能 |
| count | 统计列行数 |
| max | 求列中最大值 |
| min | 求列中最小值 |
| avg | 求列中平均值 |
| sum | 对整列求和 |
语法:
select 聚合函数(字段) from 表名;
3.1 count
求表中的行数。注意:列中的null值是不纳入计算的
select count(*) from 表名;
select count(id) from 表名;
select count(1) from 表名;
3.2 max
求某列中的最大值
select max(成绩) from 表名;
3.3 min
求某列中的最小值
select min(成绩) from 表名;
3.4 avg
求某列中的平均值
select avg(成绩) from 表名;
3.5 sum
对某列求和
select sum(成绩) from 表名;
4. 分组查询(group by)
分组的意思就是想某列相同的数据分为一组,查询出来的结果和去重功能有点相似,但是分组不是去重,去重是将有重叠的部分删除掉,重叠的那部分数据我们无法再进行操作;而通过分组出来的数据,重叠的那部分数据并消失,只是隐藏起来了,我们还是可以对重叠部分的数据进行计算的,例如进行求和运算、取最大值运算等等。
语法:where 条件可以不写
select 字段 from 表名 where 条件 group by 分组字段名 having 条件;
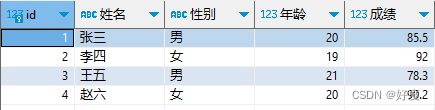
还是上面这个表, 查询男生和女生的总成绩是多少
select sum(成绩) from students s group by 性别;
5. 分组后查询条件(having)
having和where是区别的, where是在分组前使用的, having是在分组之后使用的。简单来说就是分组之后表可以作为一个整体,然后使用having对它进行条件查询。
select * from 表名 where 条件 group by 字段 having 条件;
6. 排序查询
select 字段 from 表名 order by 字段1 排序方式1, 字段2 排序方式2...;
排序方式只有两种,ASC升序,DESC降序。如果使用的升序,可以省略ASC不写。从语法可以看出来,排序是支持多字段排序的, 它的排序逻辑是先按照字段1进行排序, 如果有相同的,相同的数据在按字段2进行排序,以此类推
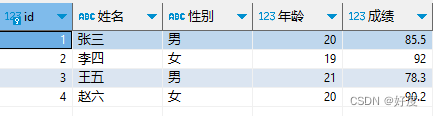
按成绩进行升序排序
select * from students order by 成绩;
按成绩进行降序排序
select * from students order by 成绩 desc;
先按成绩进行升序排序, 在按年龄进行升序排序
select * from students order by 成绩, 年龄;
7. 分页查询
select * from 表名 limit 起始索引,查询记录数;
注意1:起始索引 = (查询页数 - 1) * 查询记录数。
怎么理解这句话呢? 假如你想查询第2页, 每页显示10条数据,那么“起始索引”就等于(2-1)*10=1, 那么sql应该这么写:select * from 表名 limit 1,10; 或许你有疑惑,起始页为什么要按这个公式来呢? 不用思考太多,规则就是这样的
注意2:limit这个关键字是mysql专用的, 在oracle中是不适用的。
补充:sql语句的执行顺序
sql的编写顺序:
SELECT
字段
FROM
表名
WHERE
条件
GROUP BY
分组
HAVING
分组后条件
ORDER BY
排序
LIMIT分页参数
sql的执行顺序:









