目录
什么是缓存?
在程序中如果没有设置缓存的时候,用户想要获取到数据一般都是直接从数据库中获取。
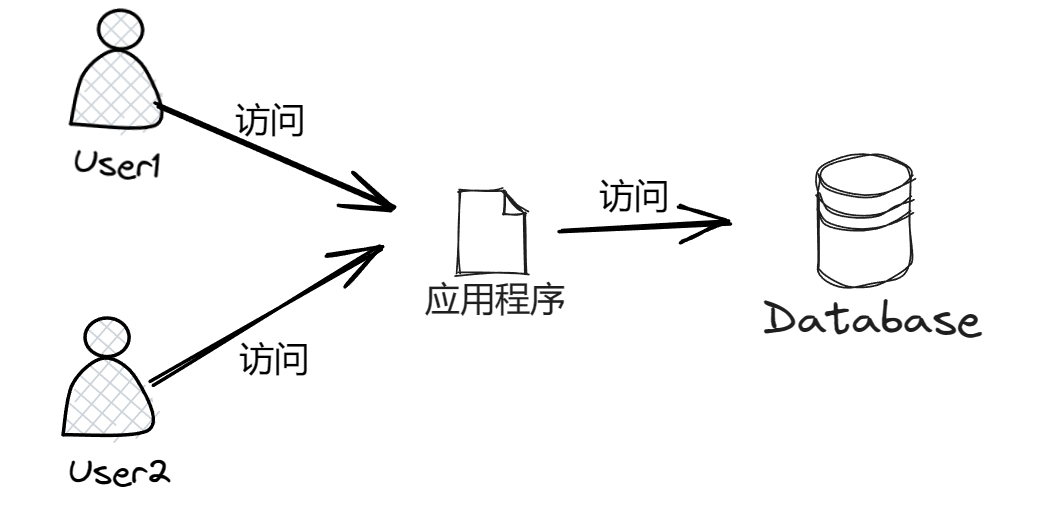
加入缓存之后会这样执行
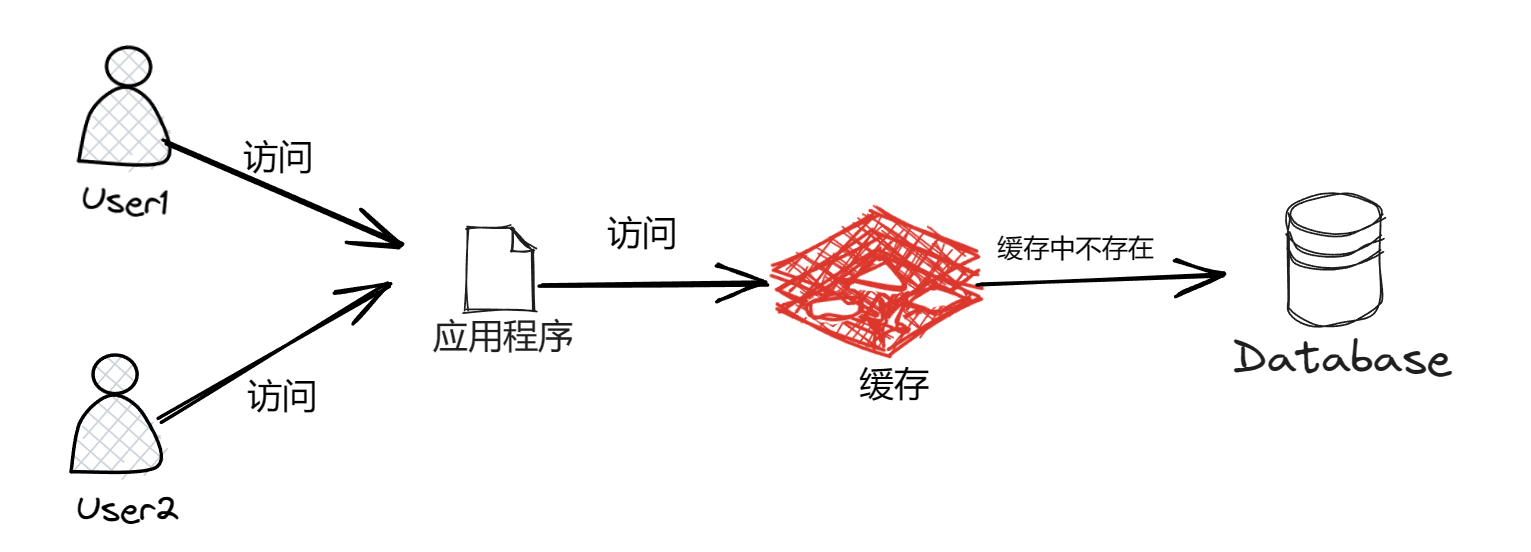
我们都知道查询数据库是一个比较慢的过程,对用户而言这样的体验是非常不好的。加入缓存之后,查询数据就会先在缓存中查找,如果缓存中没有才会去访问数据库,在数据库中查找到数据后再写回到缓存中以便后面查找,这样可以大大降低访问数据库的次数,从而减少多次访问数据库带来的压力,提高查询效率。
缓存的优点
与操作数据库相比,操作缓存会更加高效,原因如下:
- 缓存一般使用 key-value 来存储和查询数据,与查询数据库相比这种通过 key-value 方式的查询更加简单直接
- 缓存的数据存储在内存中,而数据库的数据存储在磁盘里面,访问内存的速度比访问磁盘的速度要快的多
- 缓存更容易实现分布式部署(一台服务器变成多台服务器相连的集群),而数据库比较难实现分布式部署,缓存的特性更容易平行扩展
缓存的分类
缓存可以分为以下两类:
- 本地缓存:也叫做单级缓存,简单来说就是在一台服务器上的缓存,只适用于当前的本地系统
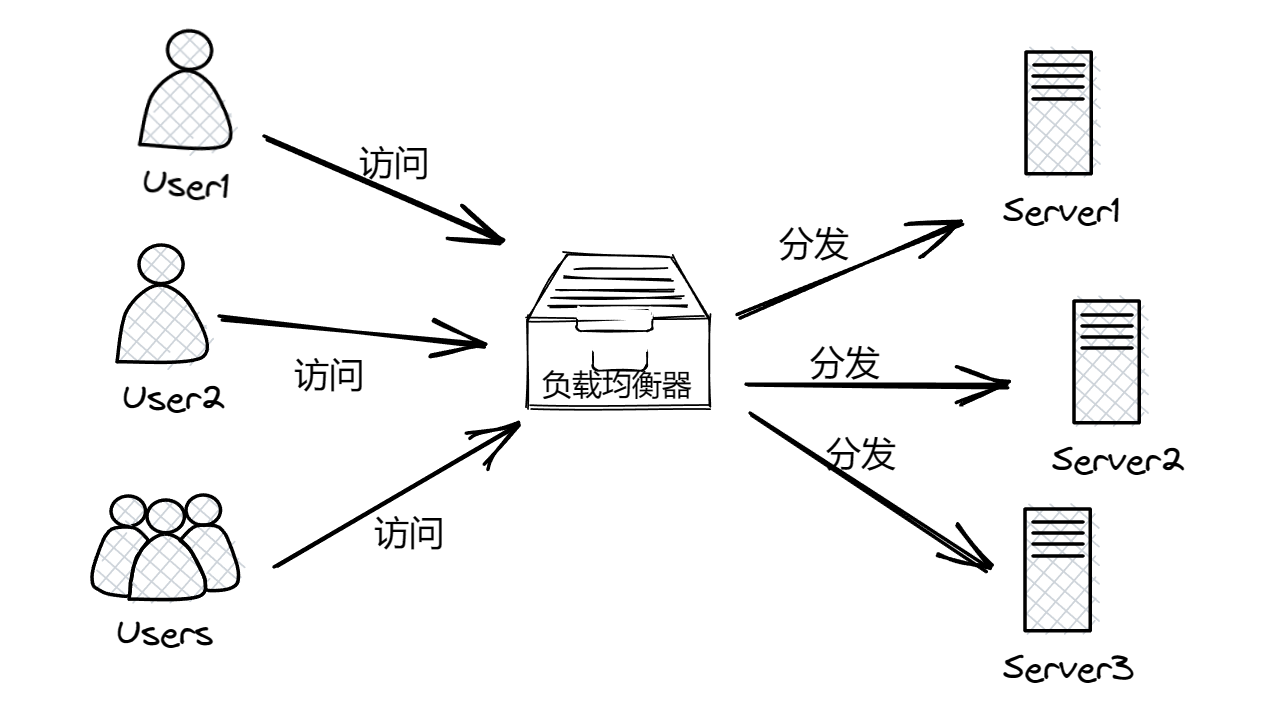
- 分布式缓存:应用在分布式系统上的缓存。分布式系统就是将一套服务器部署在多台服务器上,通过负载均衡器将用户的请求按照一定的规则分发到不同的服务器上,如下图:
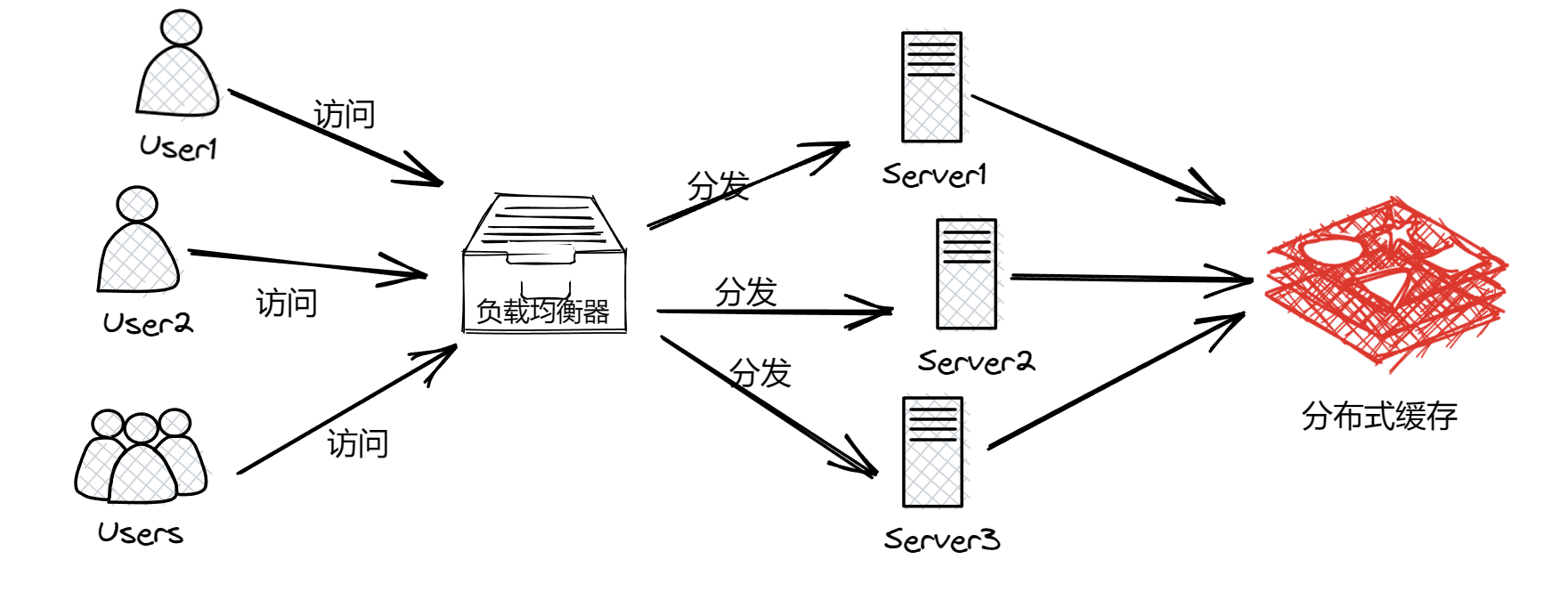
在分布式系统上加上分布式缓存之后就变成了下图过程:
缓存特性
1、缓存雪崩
缓存雪崩是指在短时间内大量的缓存同时过期,导致大量的请求直接访问数据库,进而给数据库造成巨大压力,严重的时候甚至会导致数据库宕机。
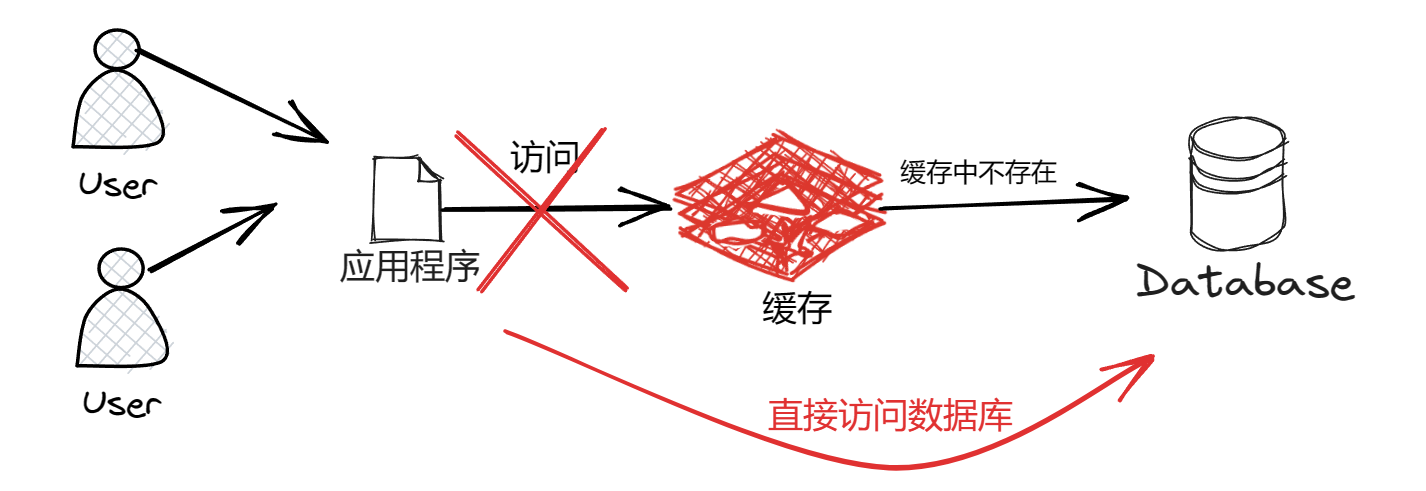
解决方法
①加锁排队:起到缓冲作用,能够防止大量请求同时操作数据库,但是增加了系统的响应时间,降低了系统的吞吐量,牺牲了一部分用户的体验。
②随机化过期时间:为了避免大量缓存同时过期,我们可以设置添加随机的时间。
// 缓存原本的失效时间
int exTime = 10 * 60;
// 随机数⽣成类
Random random = new Random();
// 缓存设置
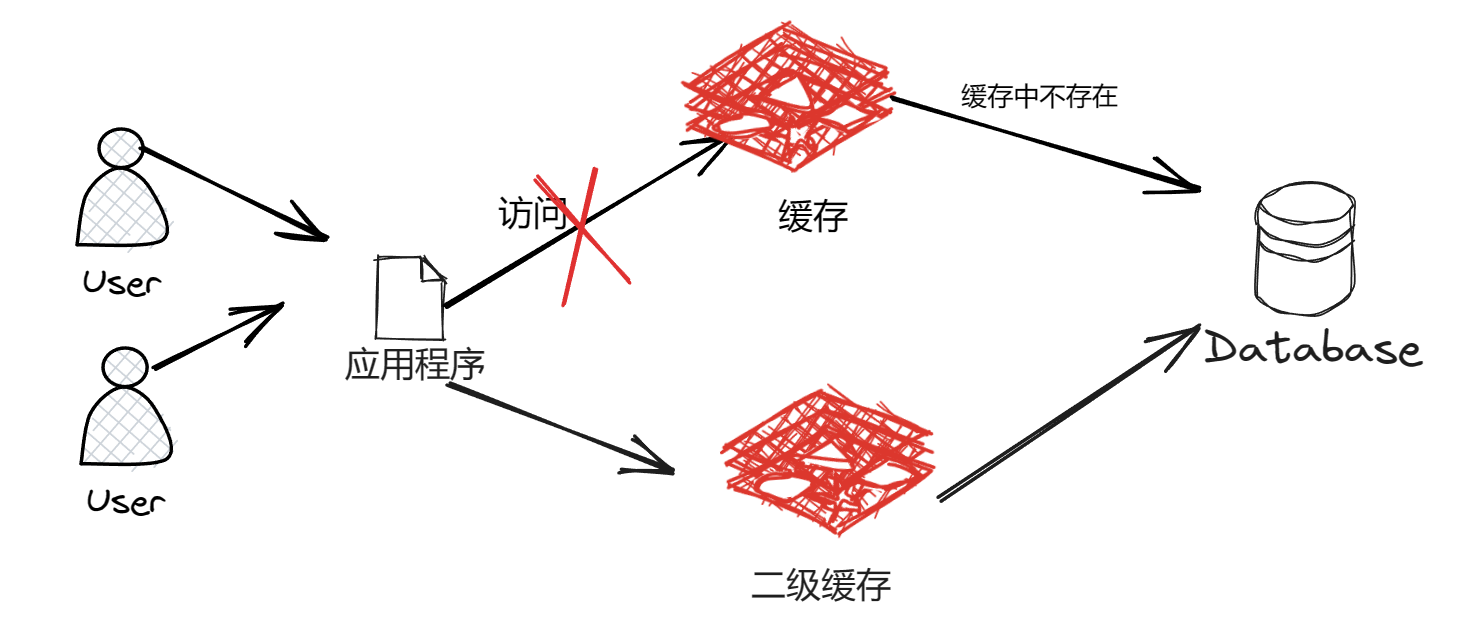
redis.setex(cacheKey, exTime+random.nextInt(1000) , value);③设置二级缓存:二级缓存是除了 Redis 本身的缓存,再设置一层缓存,当 Redis 缓存失效后,就去查询二级缓存,如下图:
2、缓存穿透
缓存穿透是指在缓存和数据库中都没有查询到数据,每次都会白白地访问数据库,如下图:
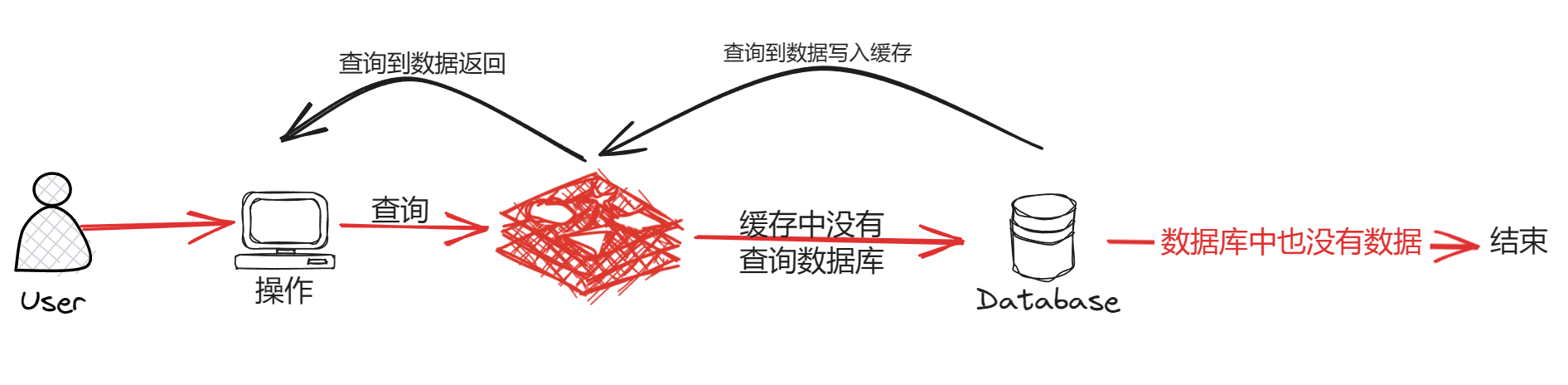
红色路线就是缓存穿透的执行路径,可以看出会白白地给数据库带来巨大的压力。
解决方法
- 缓存空结果:对查询到的空结果也保存在缓存中,如果是一个集合,那么可以保存一个空的集合,如果是缓存单个对象,可以使用字段来进行区分,避免请求穿透到数据库。
- 布隆过滤器处理:将所有可能对应的数据为空的 key 进行统一的存放,并在请求之前做拦截,避免请求穿透到数据库(这种方式实现起来相对麻烦,比较适合命中不高,但是更新不频繁的数据)。
3、缓存击穿
缓存击穿是指某个经常使用的缓存,在某一个时刻恰好失效了(例如缓存过期),并且此时恰好有大量的并发请求,这些请求就会给数据库造成巨大的压力,如下图:
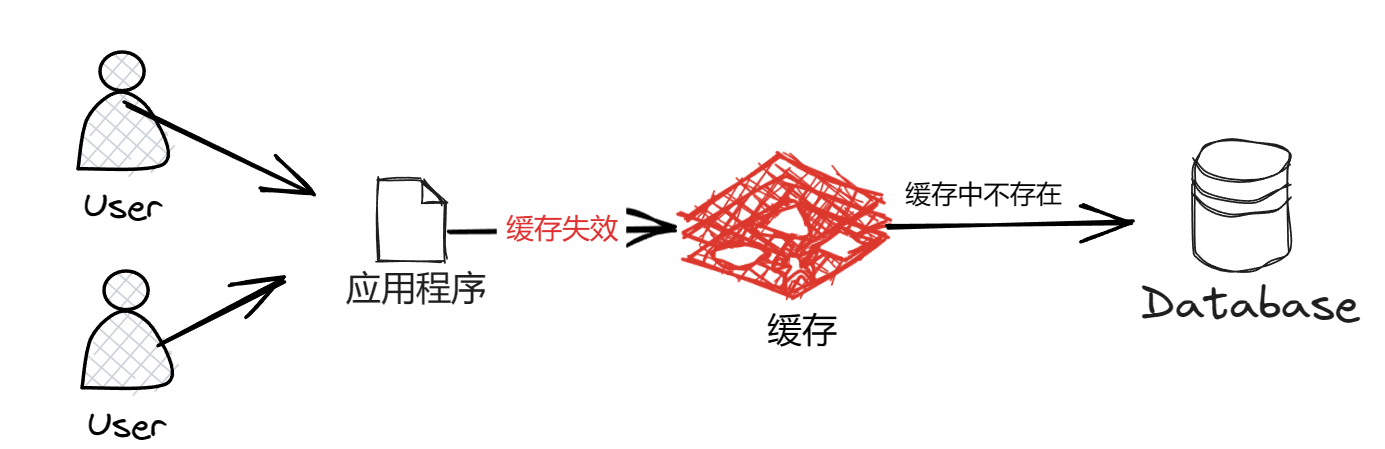
解决方法:
- 加锁排队:和处理缓存雪崩的方法类似,都是在查询数据库的时候加锁排队,缓存操作请求以此来减少服务器的运行压力。
- 设置永不过时:对于某些常用的数据,我们可以将其设置为永不过期,这样就可以保证缓存的稳定性,需要注意的是,在数据更改之后,要及时更新这个热点缓存,否则就会造成查询结果误差。
4、缓存预热
缓存预热是一种优化方案,它可以提高用户的使用体验。
缓存预热是指在系统启动的时候,先把查询结果预存到缓存中,以便于用户后面查询时可以直接从缓存中读取,节省用户的等待时间,如下图:
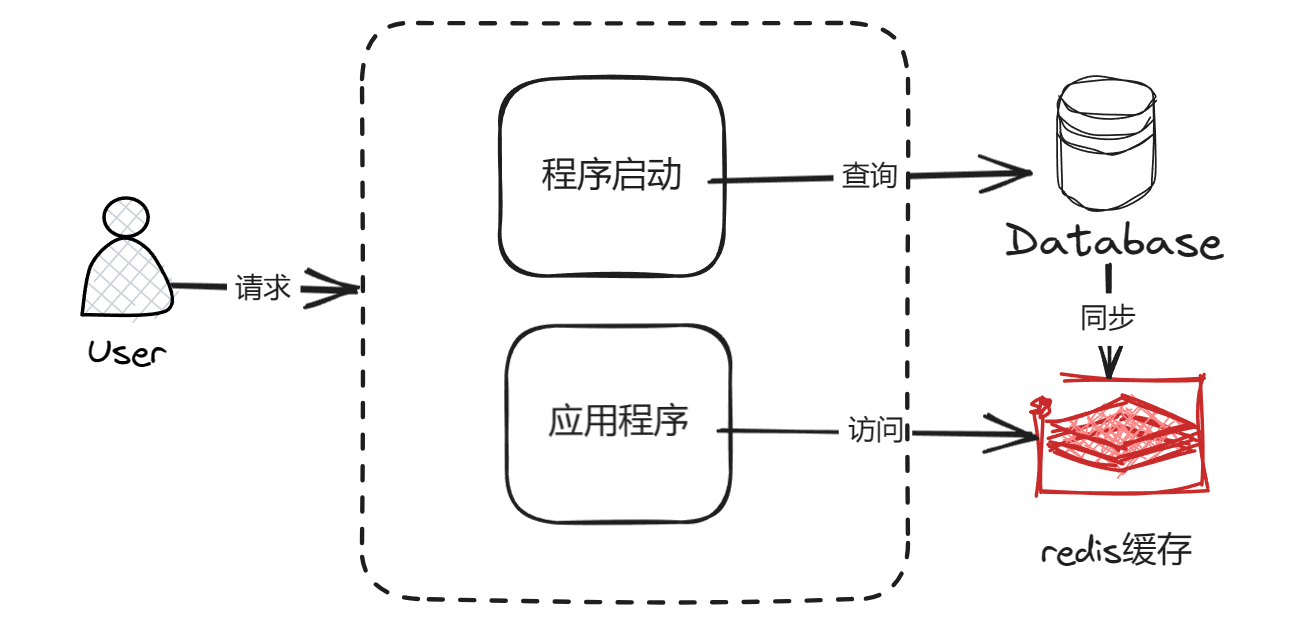
缓存预热实现思路:
- 把需要缓存的方法写在初始化的方法中,让程序启动时自动加载数据并且缓存数据。
- 把需要缓存的方法挂在某个页面或是后端接口上,手动触发缓存预热。
- 设置定时任务,定时进行缓存预热。
参考资料:https://blog.csdn.net/CYK_byte/article/details/129780182









