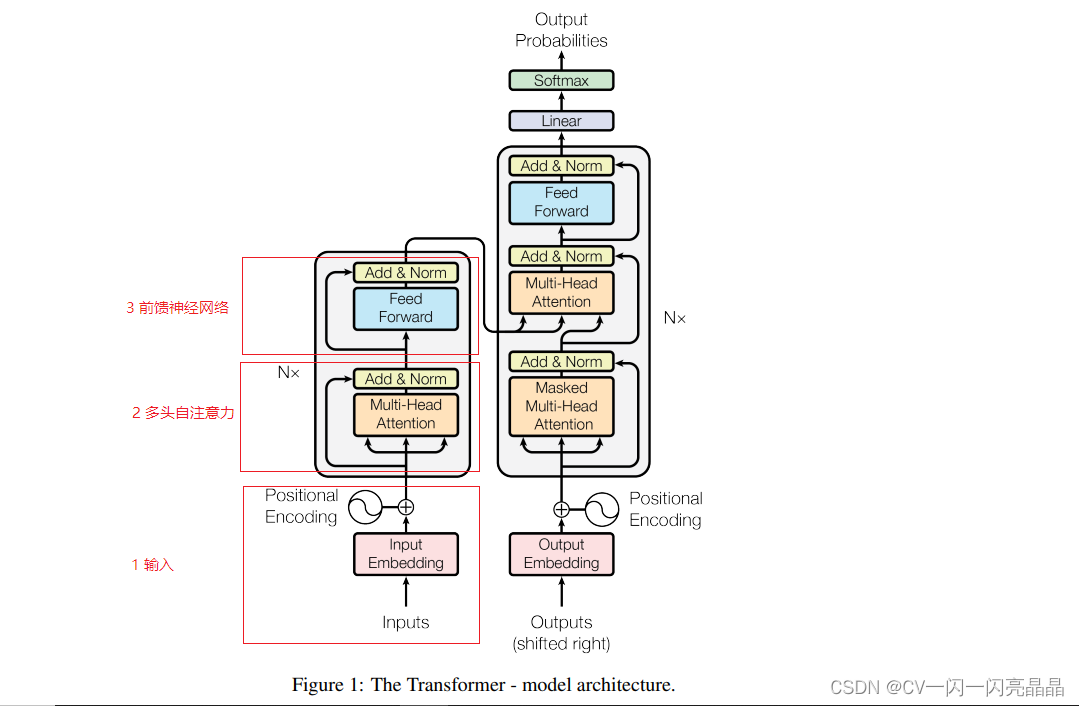
Transformer是一个序列到序列的模型,包含一个encoder和一个decoder,每个encoder或decoder均由 H个相同的结构堆叠而成。编码器模块主要包含:多头自注意力模块和前馈神经网络,同时采用残差连接增加网络深度,采用layerNorm进行归一处理。解码器模块基本结构和编码器模块相同,只是使用mask的多头注意力模块,然后增加一个交叉注意力模块,再输入逐点前馈网络,最后经过一个全连接层和一个Softmax,得到输出结果,每个输出结果又会作为下一轮decoder的输入,因此,transformer属于自回归。整体结构如上图所示,下面对每个模块进行详细解读。
Encoder
1 输入
输入部分
1.1 Embedding 词嵌入
1.1.1 Embedding 定义
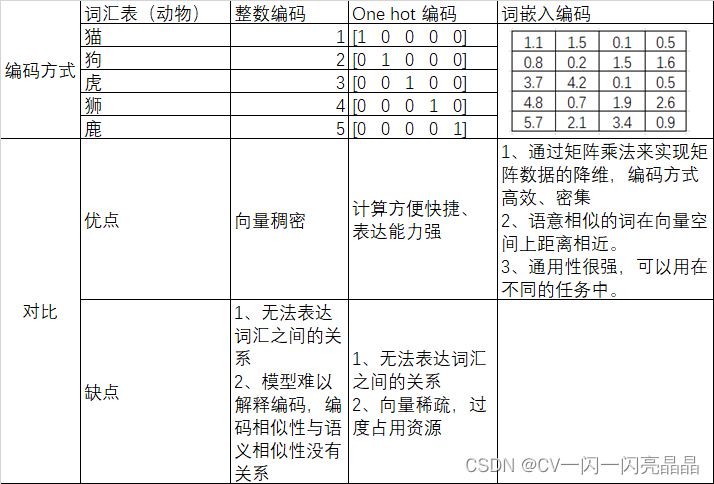
首先介绍一下常见的几种编码方式:
- 整数编码:用一种数字来代表一个词
- one-hot 编码:用一个序列向量表示一个词,该向量只有词汇表中表示这个单词的位置是1,其余都是0,序列向量长度是预定义的词汇表中单词数量。
- word embedding 词嵌入编码:将词映射或者嵌入(Embedding)到另一个数值向量空间(常常存在降维),它以one hot的稀疏矩阵为输入,经过一个线性变换(查表)将其转换成一个密集矩阵的过程。Embedding的原理是使用矩阵乘法来进行降维,节约存储空间。例如下图,一个2×6的矩阵,乘以6×3的矩阵,得到2×3的矩阵。虽然矩阵的变小,但数字蕴藏的信息没有改变,只是按照某一种映射关系将矩阵映射到一个新的维度的矩阵。每个单词都表示为一个3维的浮点值向量。可以将其理解为“查找表”,通过查找表查找密集矩阵中的值,得到每个单词进行编码。比如下面的第一个词,查找密集矩阵中第一行即可得到新的表示
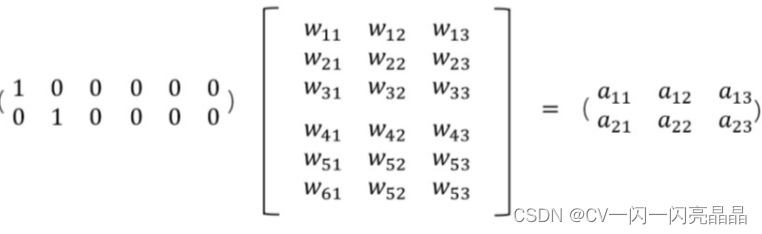
1.1.2 几种编码方式对比
下表是对几种编码方式的对比
1.1.3 实现代码
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
1.2 位置编码
1.2.1 使用位置编码原因
由于句子中的每个词语同时通过Transformer的编码器/解码器,模型本身对于每个词语的位置/顺序没有任何概念。因此,需要将词语的顺序融入到模型中,使模型能够获取词语的位置信息,也就是位置编码。位置编码需要满足以下条件:
- 词语在句子中的每个位置应输出一个唯一的编码。
- 不同长度的句子之间的任意两个位置之间的距离应保持一致。
- 模型应能适应更长的句子,其取值应该受到限制。
- 它必须是确定值。
1.2.2 位置编码方式
-
固定位置编码
-
可学习的位置编码
1.2.3 位置编码代码
2 注意力 Attention
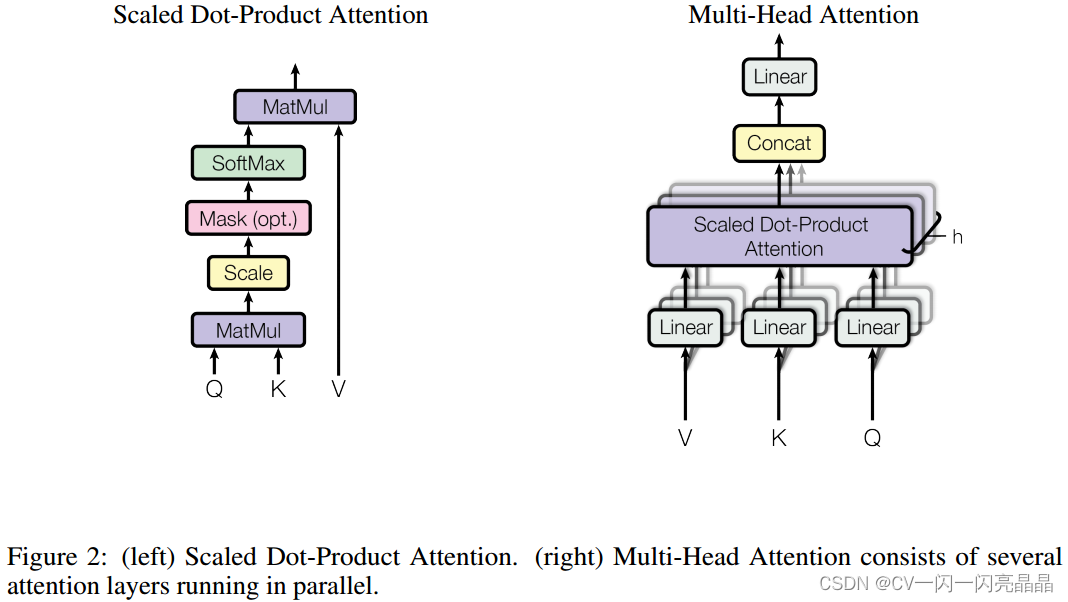
2.1 自注意力self-attention
2.1.1 QKV含义
2.1.2 自注意力公式
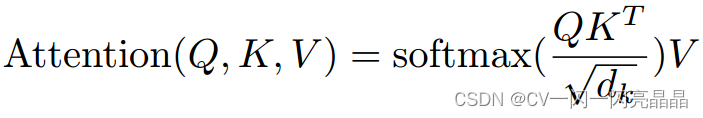
dk代表矩阵K的维度,这里进行归一化计算,假设q和k的分量是独立的随机变量,均值为0,方差为1。那么它们的点积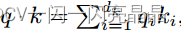 的均值为0,方差为dk,点积会变大,因此需要归一化计算。
的均值为0,方差为dk,点积会变大,因此需要归一化计算。
2.1.3 自注意力计算流程
-
对于输入的序列a1,a2,a3,a4,通过Wq,Wk,Wv三个矩阵,将其转换为q1,k1,v1,q2,k2,v2,q3,k3,v3,q4,k4,v4。
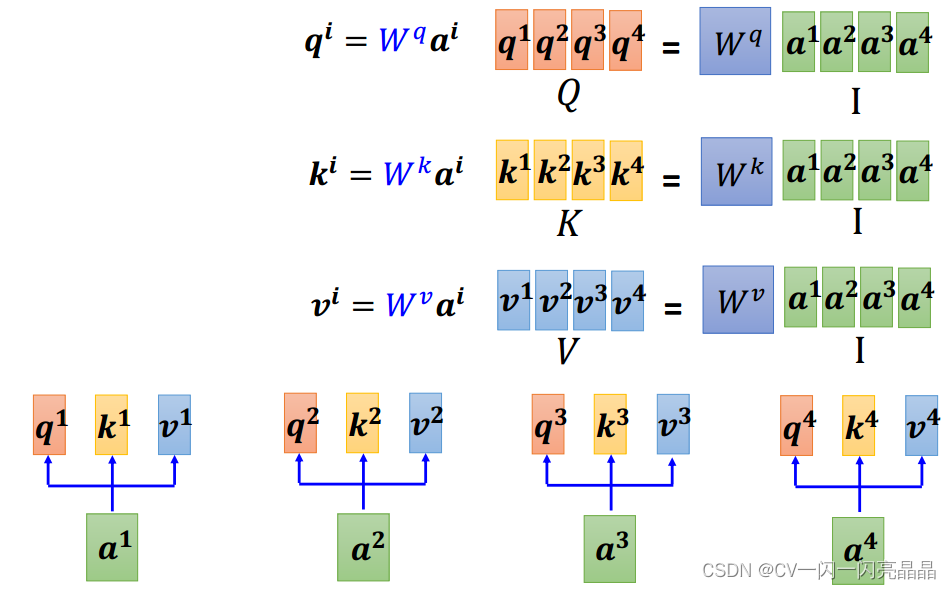
-
q1和k1—k4分别计算相似性,得到相似性系数
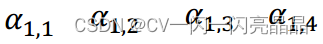
-
计算soft-max,得到
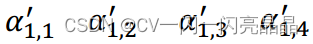
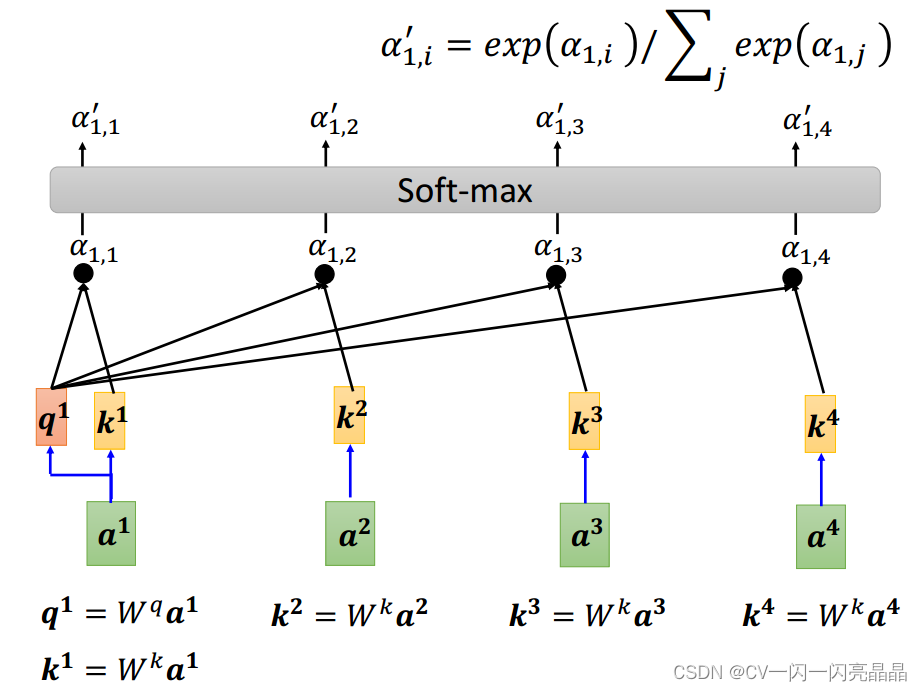
该步骤 -
将上一步得到的注意力分数与v1,v2,v3,v4相乘,求和,得到。
具体流程如下图:
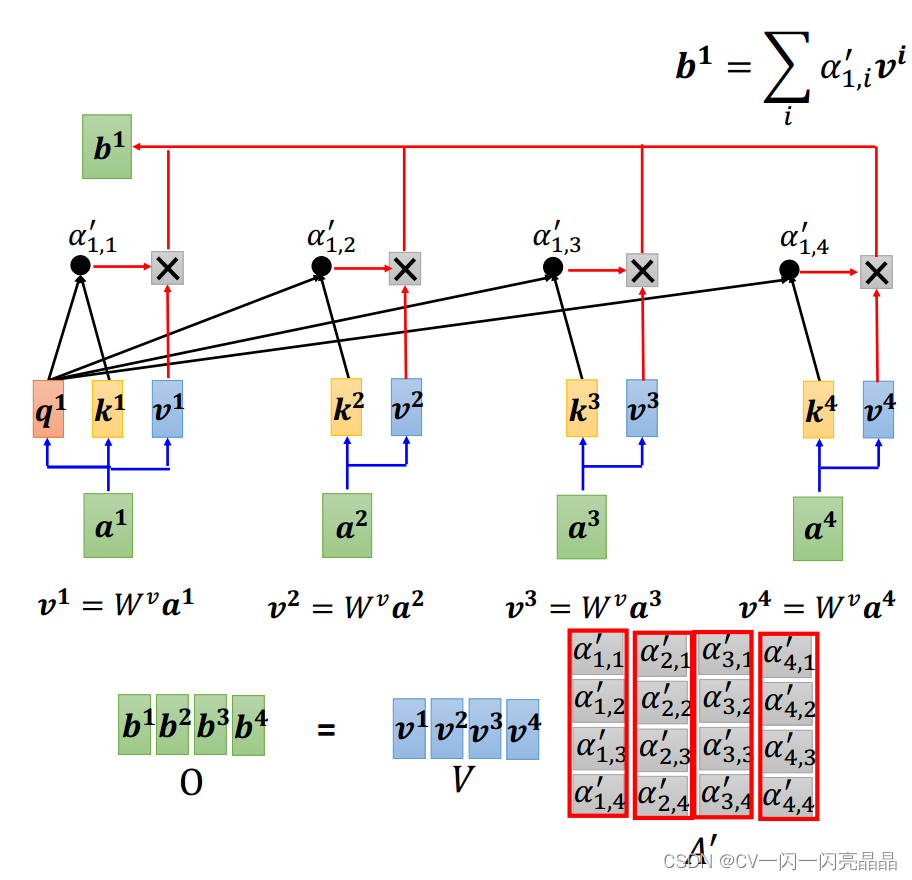
-
总结:上述流程用矩阵表示为:
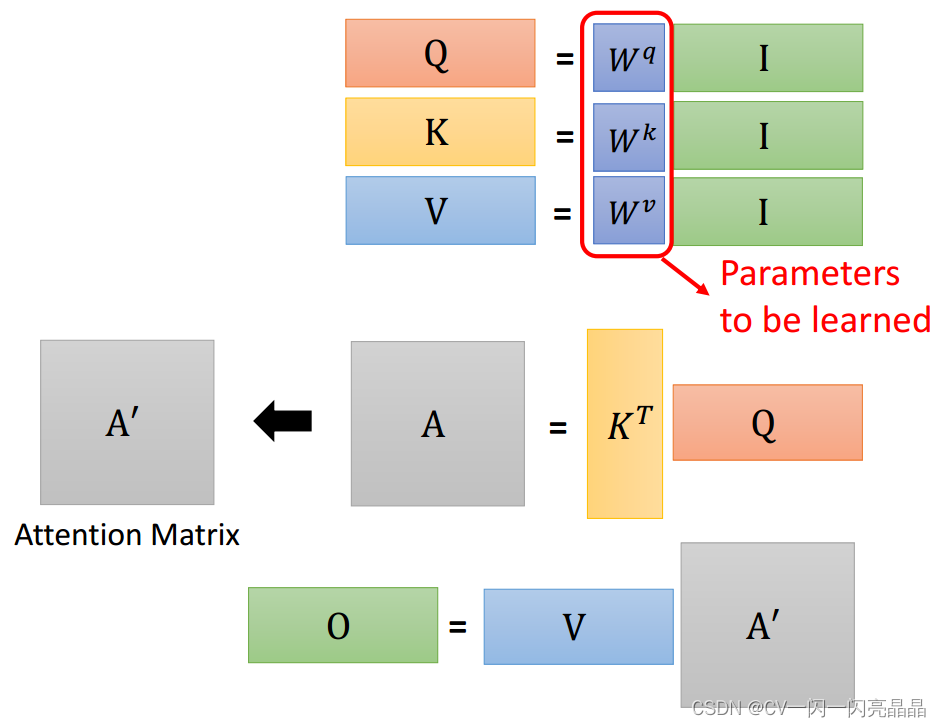
2.2 多头注意力 Multi-Head Attention
2.2.1 多头注意力公式

这里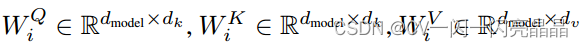 ,
,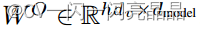
2.2.2 多头注意力计算流程
顾名思义,多头注意力就是用H个不同参数的 QKV注意力结构对输入的 Dk维度的 query,key和 value进行计算;然后将所有输出结果进行拼接,并将N*d_v维度映射回 D_m维,注意,这里的H个head是并行计算的,而不是一个一个head串行。
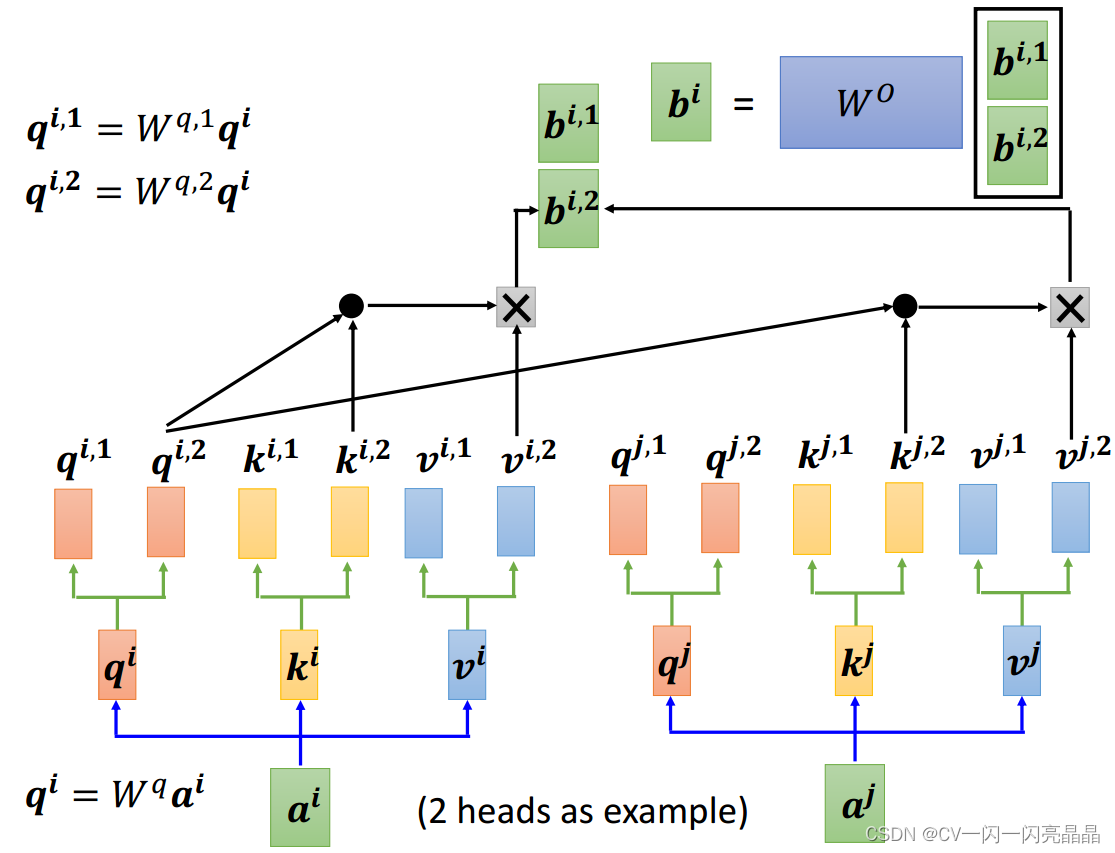
2.3 模型使用的三种注意力
- 自注意力 self attention
在 Transformer编码器中使用,Q=K=V=X, X为输入或前一层的输出 - 掩码自注意力 masked self attention
在Transformer解码器中使用,此时自注意力限制为:每个位置的 Query只注意到该位置和之前的所有 Key-Value值。具体实现为:对位归一化的注意力矩阵进行掩码操作,即当 i<j时,设置 A_ij 为负无穷。这种自注意力也称之为自回归(autogress)或因果(causal)注意力。 - 交叉注意力 cross Attention
Q,K,V的来源不同,其中 Q(query)来自于输入或上一层的输出,而 K和 V则来自于编码器的输出。
3 前馈神经网络
逐点前馈网络(Position-wise Feed-Forward Networks)为全连接(通常为两层)前馈结构,对特征图每个点进行逐点计算,计算公式为:
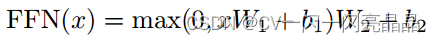
x是多头注意力的输出,第一层全连接结构经过RELU激活函数后,再计算一次全连接,W1,W2,b1,b2为可学习的参数。
4 残差连接和归一化
Transformer结构在每个模块中采用了残差连接,并对连接后的张量进行归一化操作可以表示为:
LN(X)= LayerNorm(x + Sublayer(x))
Sublayer表示当前层的操作,比如当前层计算多头注意力,这里就是Multihead(x),若是逐点前馈网络,就是FFN(x),LayerNorm表示层归一化操作。残差连接和归一化主要用于构建更深的网络结构,减缓梯度消失问题。
Decoder
1 输入
Decoder的输入部分与Encoder类似,都是将输入先经过embedding转换,然后增加位置编码,区别是,这里的输入是Decoder上一轮的输出结果,因此,transformer是自回归。
2 mask 多头自注意力
Decoder也有多头自注意力(MHA)模块,不过这里需要对当前单词和之后的单词做mask,也就是模型只会看到当前位置之前的内容,这样,才能确保预测仅依赖于已生成的输出单词。
3 多头交叉注意力
交叉注意力也成为跨注意力,这里的K和V是来源于encoder的输出,Q是来源于Decoder的Mask MHA,而解码器自注意力中,Q、K和V都来自上一个解码器层的输出。
4 前馈神经网络
这部分和encoder相同,不再赘述
5 输出
经过decoder后,网络再经过全连接层和softmax,即可得到输出结果
参考内容:
感谢李宏毅老师的视频讲解,文章中的图来源于李老师的PPT。





