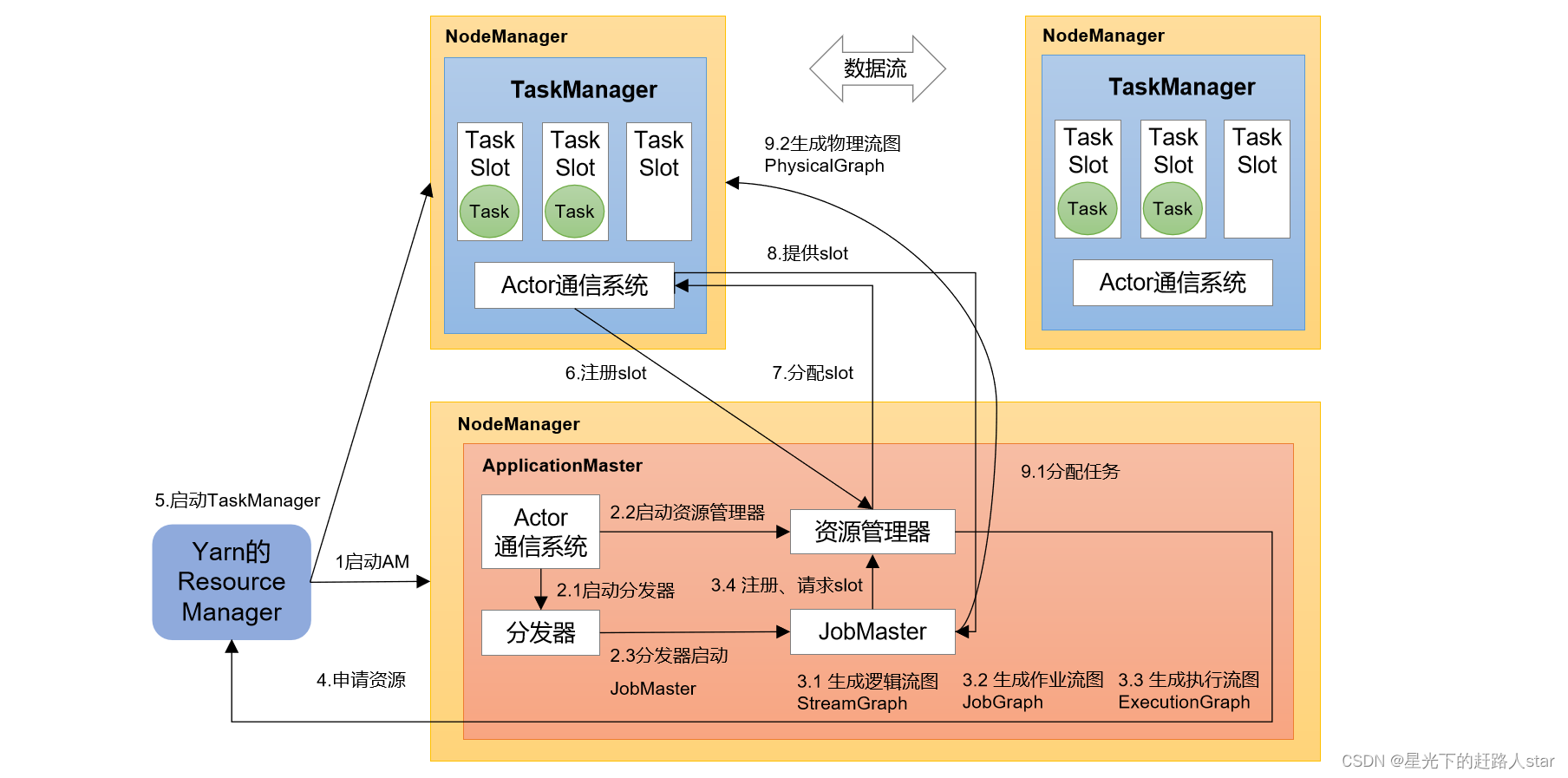
1、系统架构(以Standalone会话模式为例)

1、作业管理器(JobManager)
JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。
JobManager又包含三个不同的组件
(1)JobMaster
JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。所以JobMaster和具体的Job是一一对应的,多个Job可以同时运行在一个Flink集群中,每个Job都有一个自己的JobMaster。需要注意的是,在早期的Flink中,没有JobMaster的概念,而JobManager的概念范围比较小,实际指的就是现在所说的JobMaster。
在作业提交的时候,JobMaster会先接受到要执行的应用。JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图就叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
而在运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(Checkpoint)的协调。
(2)资源管理器(ResourceManager)
ResourceManager主要负责资源的分配和管理,在Flink集群中只有一个。所谓资源,主要是指TaskManager的任务槽(Slot)。任务槽就是Flink集群中的资源调度单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个Slot上执行。
这里主要要把FLink内置的ResourceManager和其他资源平台的(比如YARN)的ResourceManager区分开。
(3)分发器(Dispatcher)
Dispatcher主要负责提供一个Rest接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的JobMaster组件。Dispatcher也会启动一个Web UI,用来方便展示和监控作业执行的信息。Dispatcher在架构中不是必须的,在不同的部署模式下可能会被忽略掉。
2、任务管理器(TaskManager)
TaskManager是Flink中的工作进程,数据流的具体计算就是它来做的。Flink集群中必须至少有一个TaskManager;每一个TaskManager都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,Slot的数量限制了TaskManager能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令之后,TaskManager就会将一个或者多个槽位通过JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。
2、核心概念
2.1 并行度(Parallelism)
1、并行子任务和并行度
当要处理的数据量非常大的时候,我们可以把一个算子操作,复制多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分了多个并行的‘子任务’(subTasks),再将它们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(Operator)可以包含一个或多个子任务(Operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立的执行。

一个特定算子的子任务(subtask)的个数被称之为其并行度(Parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(Stream Partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所示,当前数据流中有Source、map、window、sink四个算子,其中sink的并行度是1,其他算子的并行度都是2,。所以这段流处理程序的并行度就是2。
2、并行度的设置
在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
(1)代码中设置
我们在代码中,可以很简单的在算子后面跟着调用setParallelism()方法,来设置当前算子的并行度;
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
这种方式设置的并行度只针对当前算子有效。
另外,我们也可以直接调用执行环境的setParallelism()方法,全局设置并行度 ;
env.setParallelism(2);
这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是普通算子,所以无法·1对keyBy设置并行度。
(2)提交应用时设置
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置;
bin/flink run –p 2 –c com.zhm.wc.SocketStreamWordCount
./FlinkTutorial-1.0-SNAPSHOT.jar
(3)配置文件中设置
我们还可以直接在集群的配置文件flink-conf.yaml中直接更改默认并行度;
parallelism.default: 2
这个设置对于整个集群上提交的所有作业有效,初始值为1.无论在代码中设置、还是提交时的-p参数都不是必须的;所以在没有指定并行度的时候,就会采用配置文件中的集群默认并行度。在开发环境中,没有配置文件,默认并行度就是当前集群的cpu核心数。
优先级是:算子后面>代码中env设置>提交应用时>配置文件中>当前机器的CPU核心数
2.2 算子链(Operator Chain)
1、算子间的数据传输
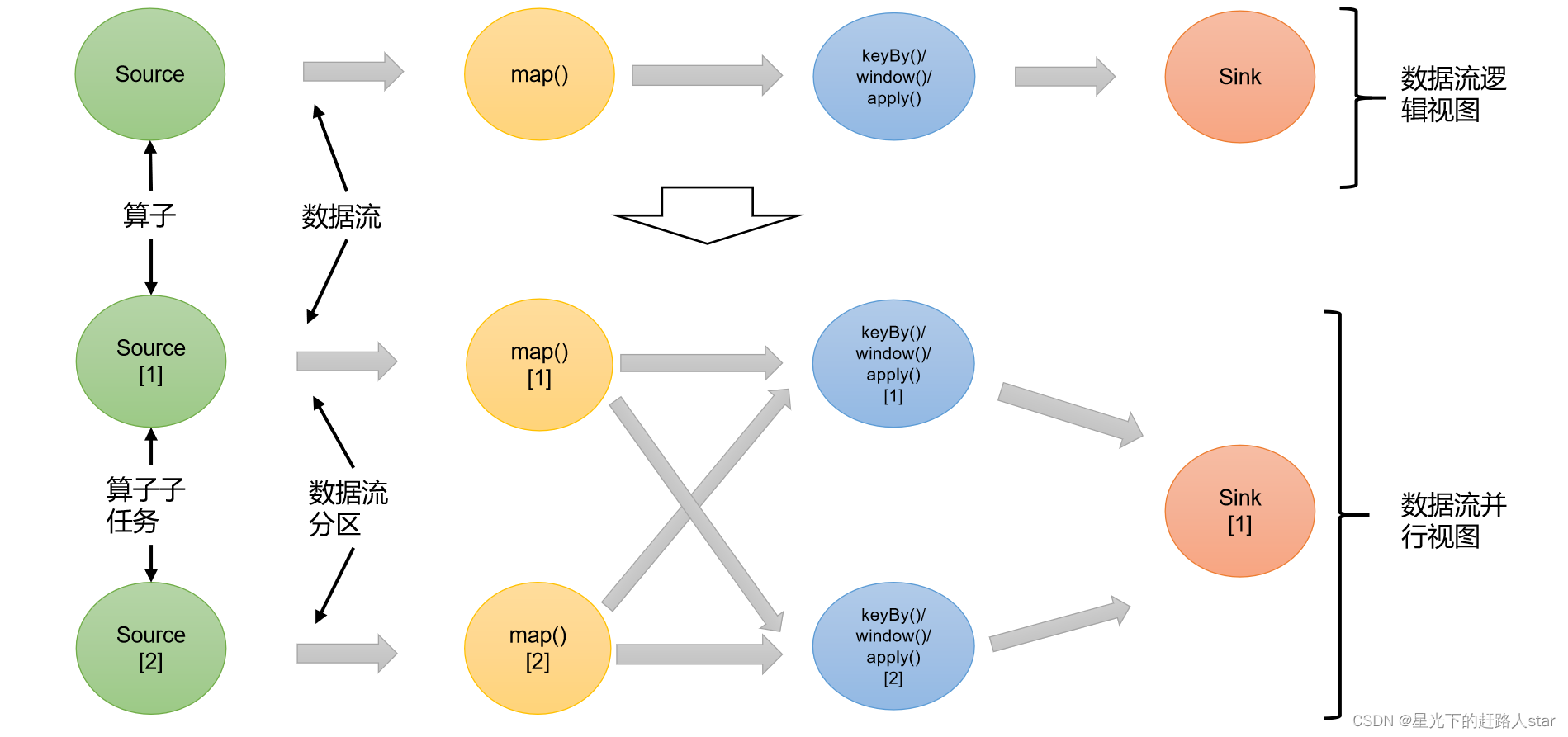
一个数据流在算子之间传输数据的形式可以是一对一(one to one )的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
(1)一对一(one to one ,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的Source和map算子,Source算子读取数据之后,可以直接发送给map算子处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着map算子的子任务,看到元素个数和顺序跟Source算子的子任务产生的完全一样,保证着一对一的关系。map、filter、flatMap等算子都是这种one to one 的对应关系。这种关系类似于Spark中的窄依赖。
(2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比如图中的map和后面的keyBy/window算子之间,以及keyBy/window算子和Sink算子之间都是这样的关系。
每一个算子的子任务会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle。
2、合并算子链
在Flink中,并行度相同的一对一(one to onr )算子操作,可以直接链接在一起形成一个“大”的任务(Task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
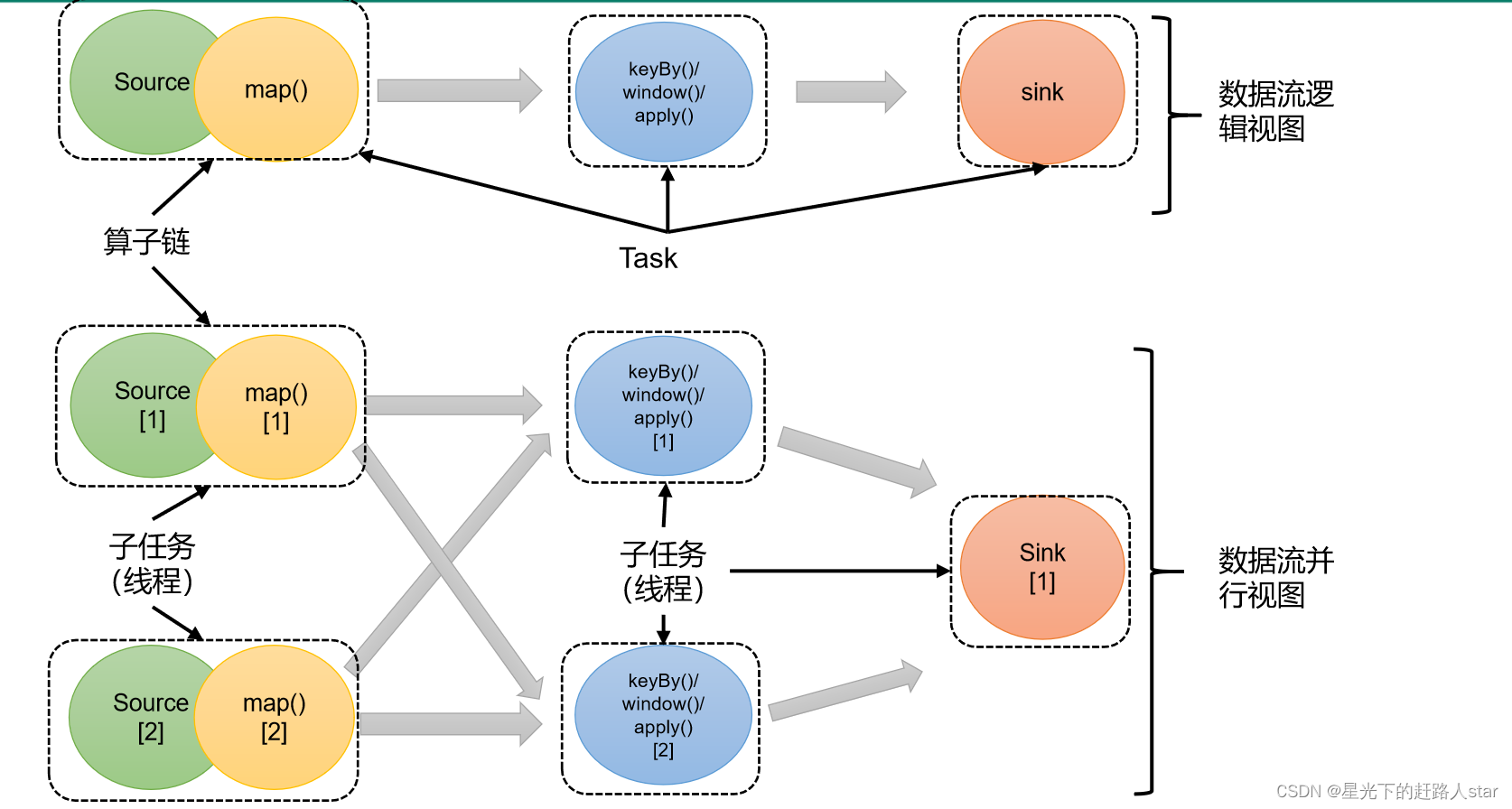
上图中Source和map之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度是2,所以合并后的任务也有两个并行子任务。这样,这个数据流图所表示的作业最终会有5个任务,由5个线程并行执行。
将算子链接成task是非常有效的优化;可以减少线程之间的切换和基于缓冲区的数据交换,在减少时延的同时提升吞吐量。
Flink默认会按照算子链的原则进行链接合并,如果我们需要禁止合并或者自行定义,也可以在代码中对算子做一些·特定的设置:
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()
2.3 任务槽(Task Slots)
1、任务槽(Task Slots)
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务。
很显然,TaskManager的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一个TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要再TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
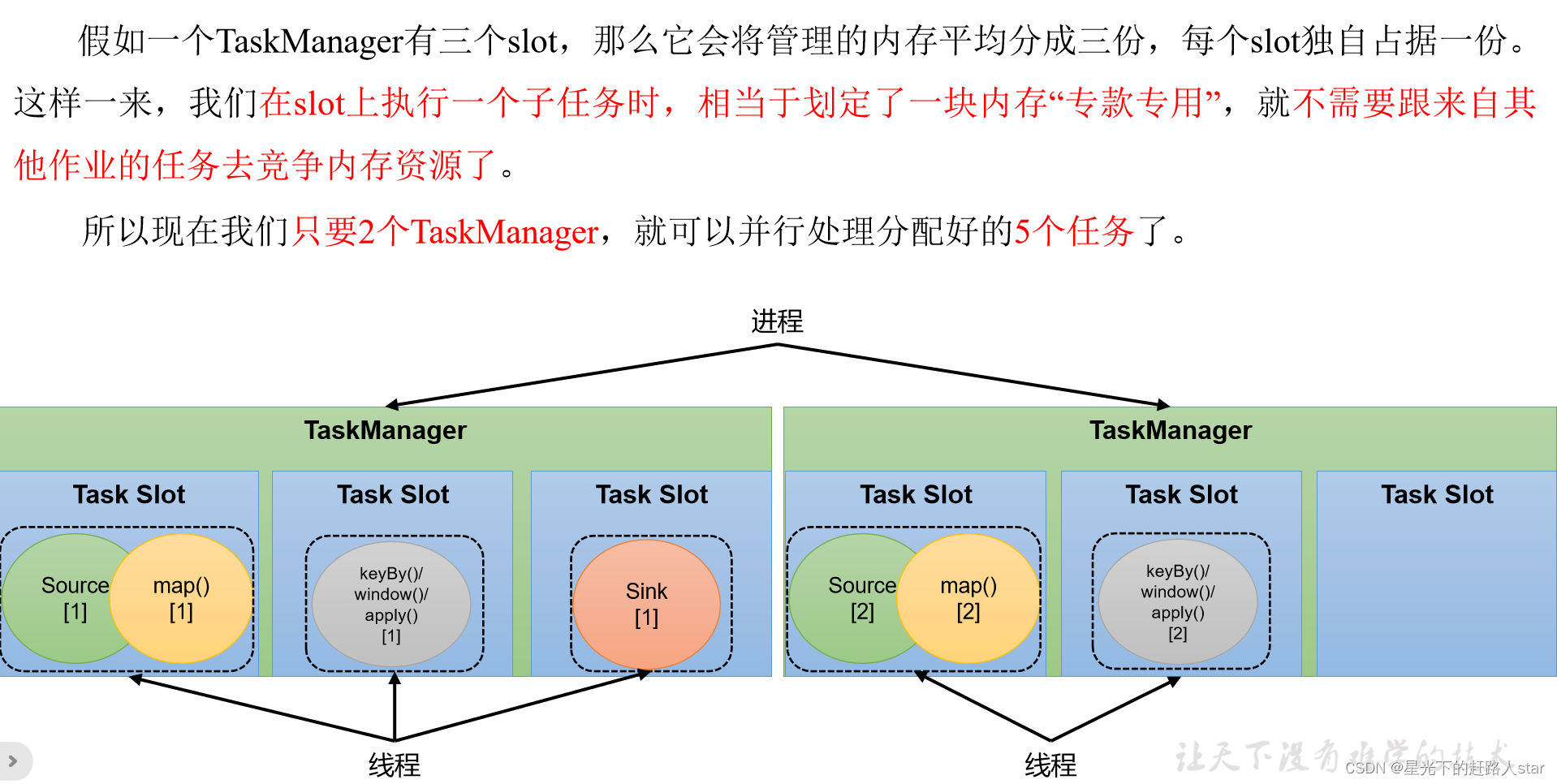
2、任务槽数量的设置
在Flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中,可以设置TaskManager的slot数量,默认是1个slot。
taskmanager.numberOfTaskSlots: 8
需要注意的是,slot目前仅仅用来隔离内存的,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争。这也是开发环境默认并行度设为机器CPU数量的原因。
3、任务对任务槽的共享
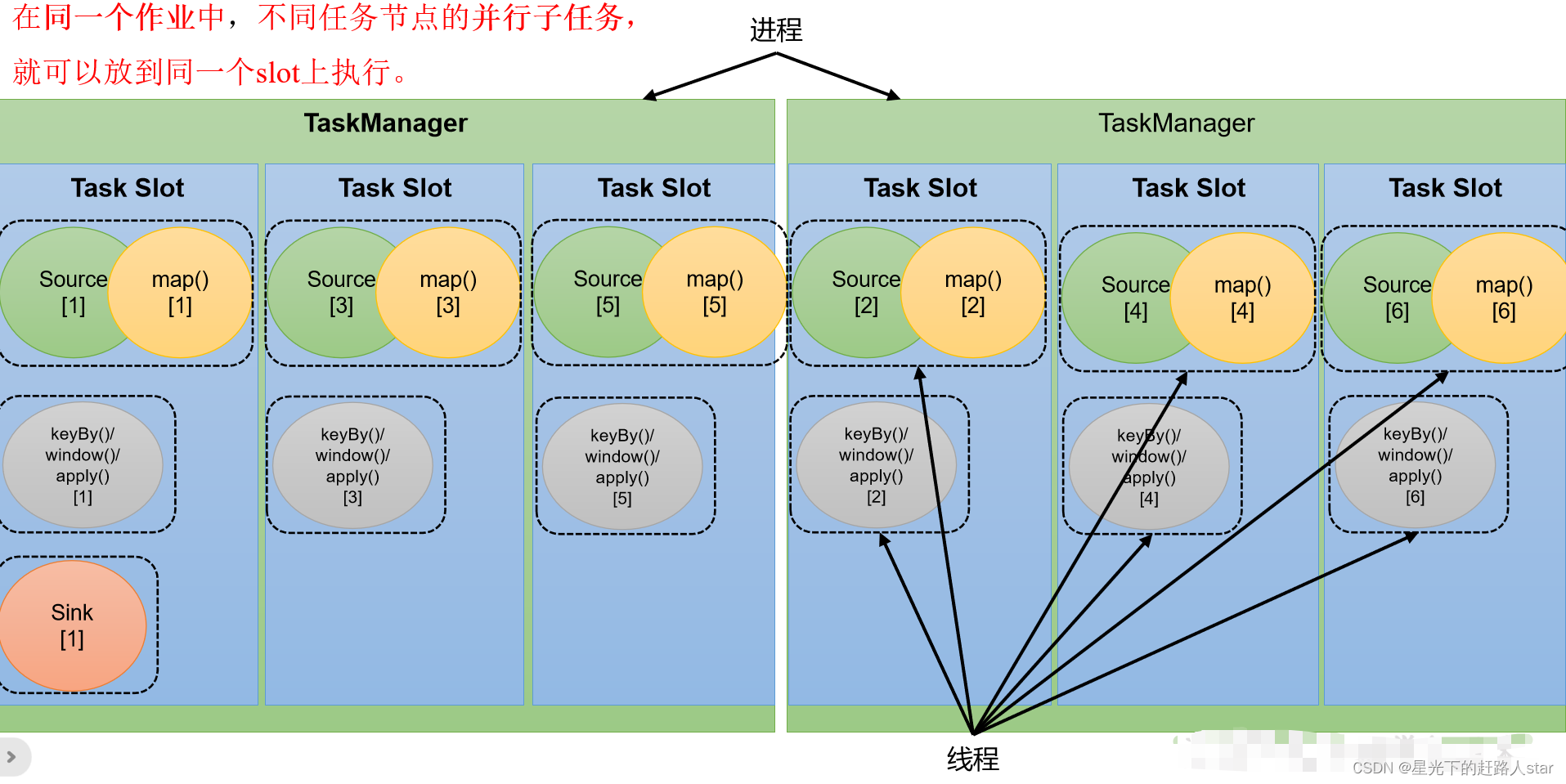
默认情况下,Flink是运行子任务共享slot的。如果我们保持sink任务并行度为不变,而提交作业时设置全局并行度为6,那么前两个任务节点就会各自有6个并行子任务,整个流处理程序则有13个子任务。如上图所示,只要属于同一个作业,那么对于不同任务节点(算子)的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点Source->map,它的6个并行子任务必须分配到不同的slot上,而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自习分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。
slot共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
当然,Flink默认是允许slot共享的,如果希望某个算子对应的任务完全独占一个slot,或者只有某一部分算子共享slot,我们也可以通过设置“slot共享组”手动指定:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup("1");
这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的slot上。在这种场景下,总共需要的slot数量,就是各个slot共享组最大并行度的总和。
2.4 任务槽和并行度的关系
任务槽和并行度都跟程序的并行执行有关,但两者是完全不同的概念。简单来说任务槽式静态的概念,是指是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
举例说明:假设一共有3个TaskManager,每一个TaskManager中的slot数量设置为3个,那么一共有9个task slot,表示集群最多能并行执行9个同一算子的子任务。
而我们定义word count程序的处理操作是四个转换算子:
source→ flatmap→ reduce→ sink
当所有算子并行度相同时,容易看出source和flatmap可以合并算子链,于是最终有三个任务节点。
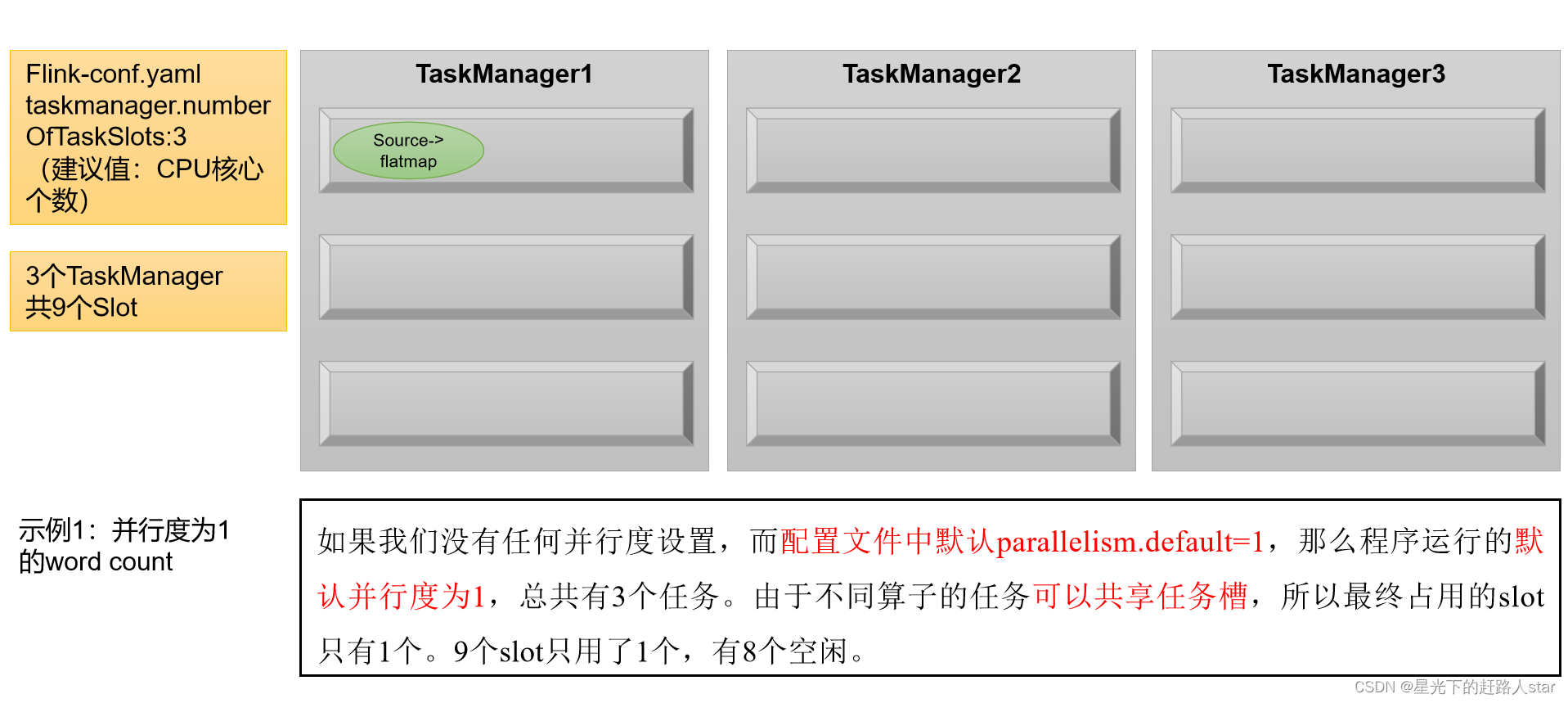



通过这个例子也可以明确看出,整个流处理程序的并行度,就应该是所有算子并行度中最大的那个,这代表了运行程序所需要的slot数量
3、作业提交流程
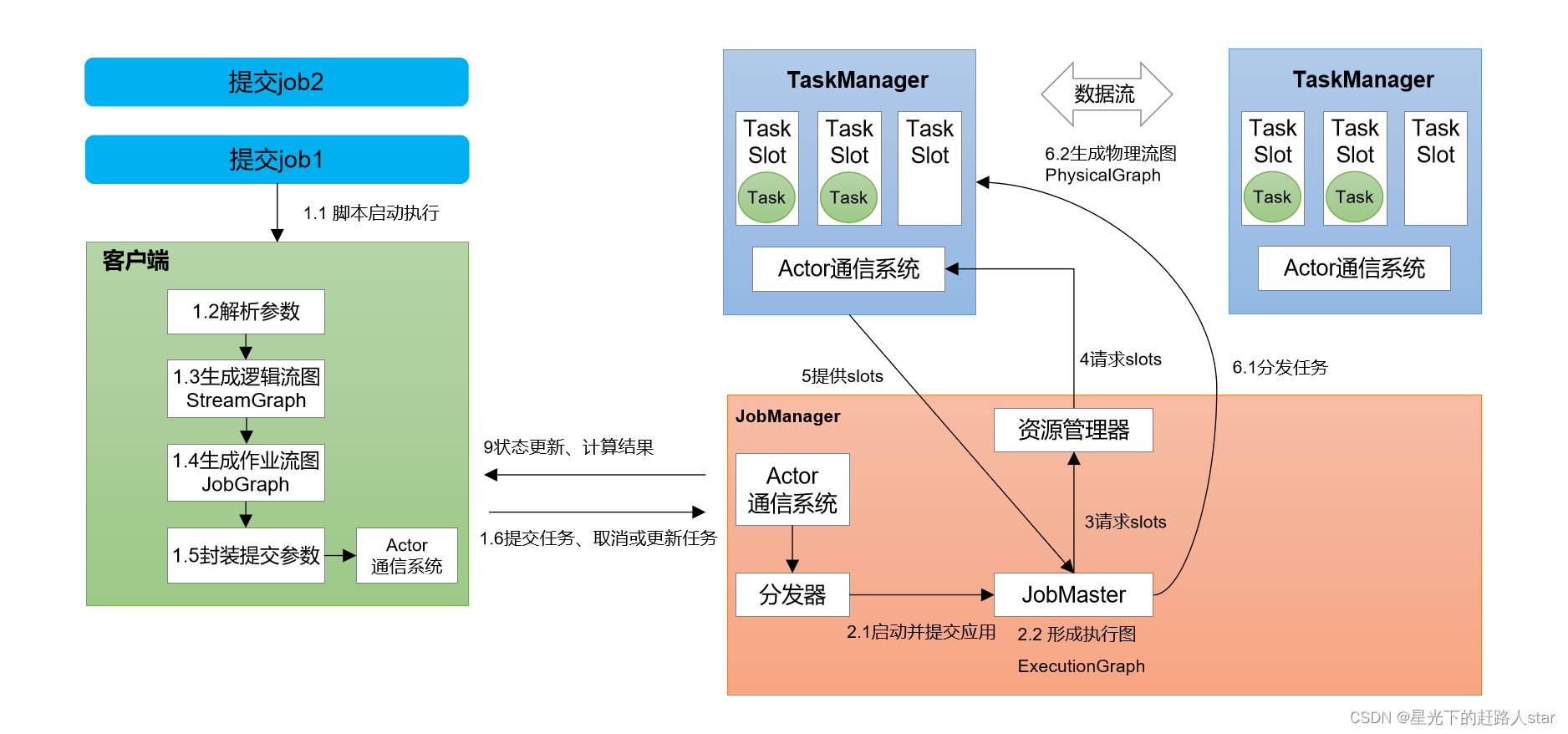
3.1 Standalone会话模式作业提交流程
3.2 逻辑流图/作业图/执行图/物理流图
我们已经彻底了解了由代码生成任务的过程,现在来做个梳理总结。
逻辑流图(Stream Graph)->作业图(JobGraph)->执行图(ExecutionGraph)->物理图(Physical Graph)。
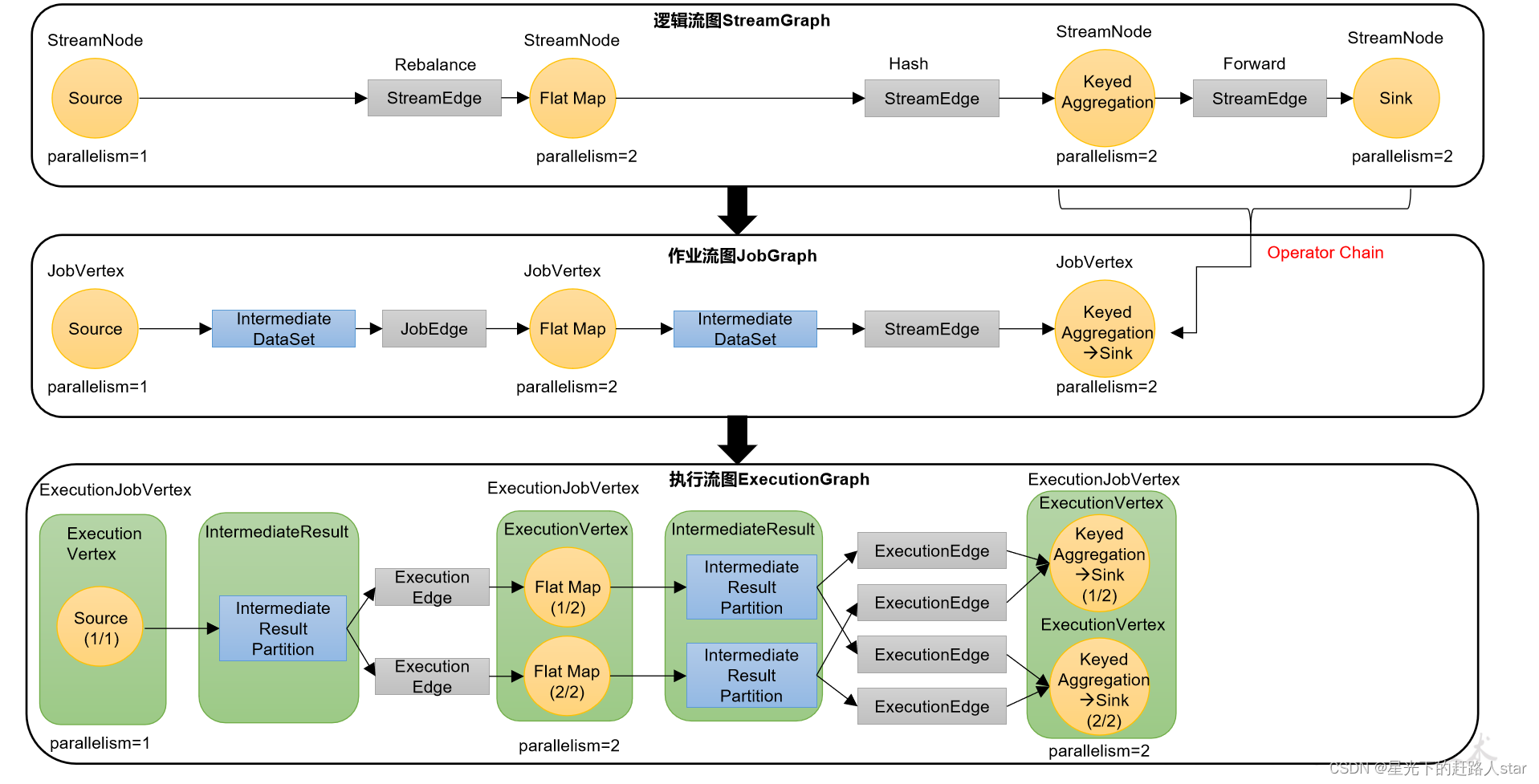
1、逻辑流图(StreamGraph)
这是根据用户通过 DataStream API编写的代码生成的最初的DAG图,用来表示程序的拓扑结构。这一步一般在客户端完成。
2、作业图(JobGraph)
StreamGraph经过优化后生成的就是作业图(JobGraph),这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为:将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph一般也是在客户端生成的,在作业提交时传递给JobMaster。
我们提交作业之后,打开Flink自带的Web UI,点击作业就能看到对应的作业图。

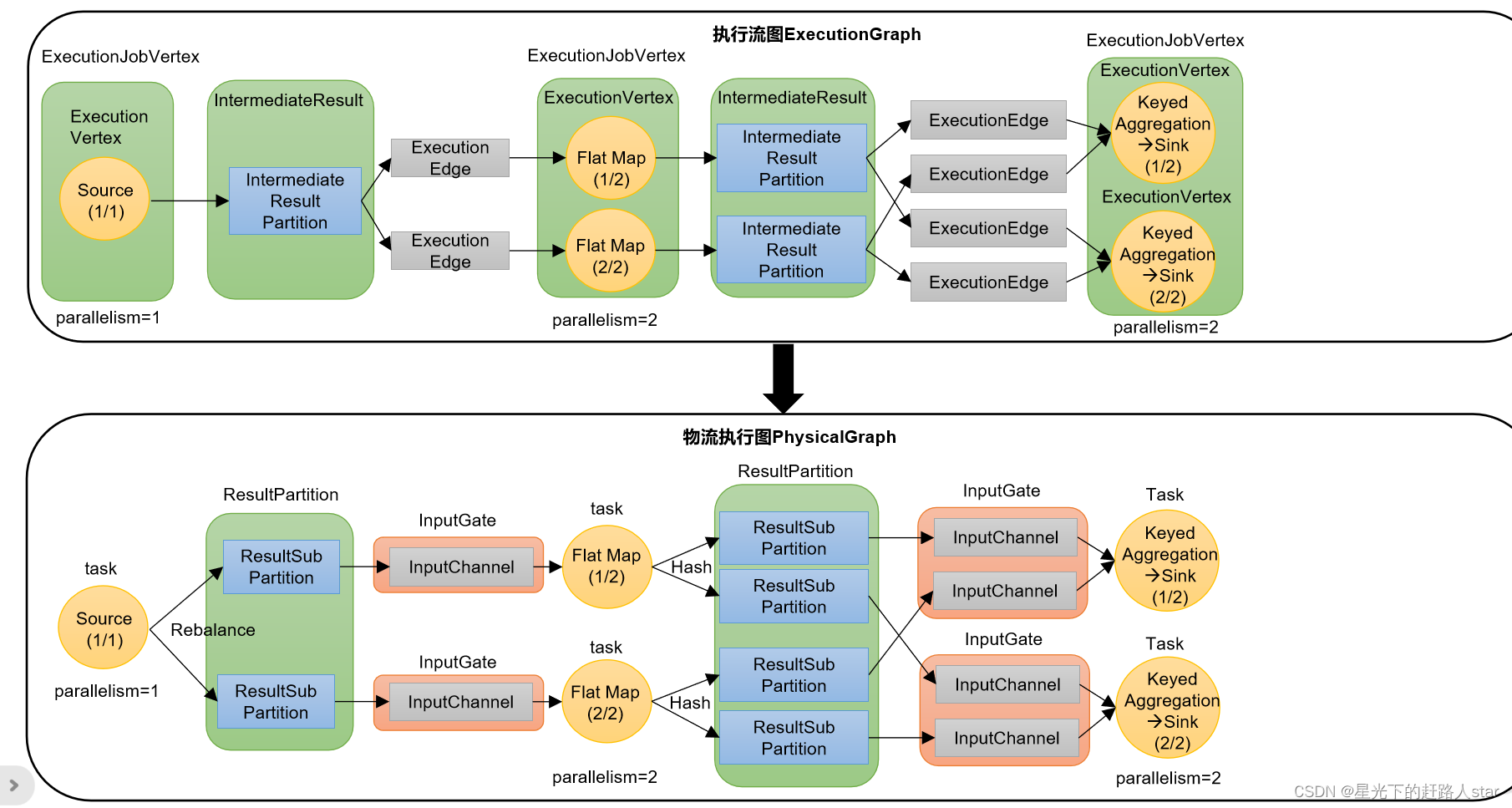
3、执行图(ExecutionGraph)
JobMaster收到JobGraph后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。与JobGraph最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
4、物理图(PhysicalGraph)
JobMaster生成执行图后,会将它分发给TaskManager;各个TaskManager会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。这只是具体执行层面的图,并不是一个具体的数据结构。
物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager就可以对传递来的数据进行处理计算了。
3.3 Yarn应用模式作业提交流程