目录
队列的讲解将建立在有双向链表的基础之上进行讲解
当然队列只是链表的一种分支
单项链表详解:# 数据结构:线性表之-单向链表(无头)
双向链表详解:# 数据结构:线性表之-循环双向链表(万字详解)
什么是队列?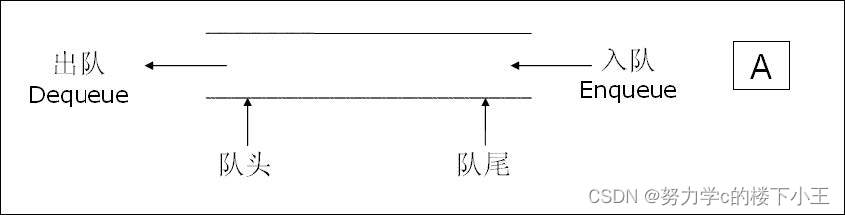
队列是一种常见的数据结构,用于存储和管理数据的集合。它遵循先进先出(FIFO)的原则,即最先进入队列的元素最先被删除。类比一下,你可以把队列视为排队等待服务的人群,新来的人排在队列末尾,而需要服务的人从队列头部被依次处理。
队列通常有两种基本操作:
- 入队(enqueue):将元素添加到队列的末尾。
- 出队(dequeue):从队列的头部删除一个元素,并返回被删除的元素。
除了入队和出队操作,队列还可以支持其他操作,如获取队列的大小(元素个数)、判断队列是否为空等。队列在计算机科学中有广泛的应用,例如任务调度、缓冲区管理、计算机网络等领域。
当队列已满时,新的元素无法入队,我们称之为队列满(Queue Full)。
当队列为空时,没有元素可以出队,我们称之为队列空(Queue Empty)。
队列的实现方式有多种,最常见的是使用数组或链表来存储元素。在数组实现中,我们使用一个固定大小的数组来存储元素,并使用两个指针(front和rear)分别指向队列的头部和尾部。入队操作时,将元素添加到rear指针所指位置,并将rear指针向后移动一位;出队操作时,将front指针所指位置的元素删除,并将front指针向后移动一位。
队列的应用非常广泛。举例来说,在计算机的操作系统中,进程调度算法通常使用队列来管理待执行的进程。在网络数据传输中,数据包也会按照先后顺序排队等待传输。此外,实现广度优先搜索算法、缓冲区处理等也需要使用队列。队列数据结构的特性使得它在这些场景下非常实用,能够提高程序的效率和性能。
详解:
功能介绍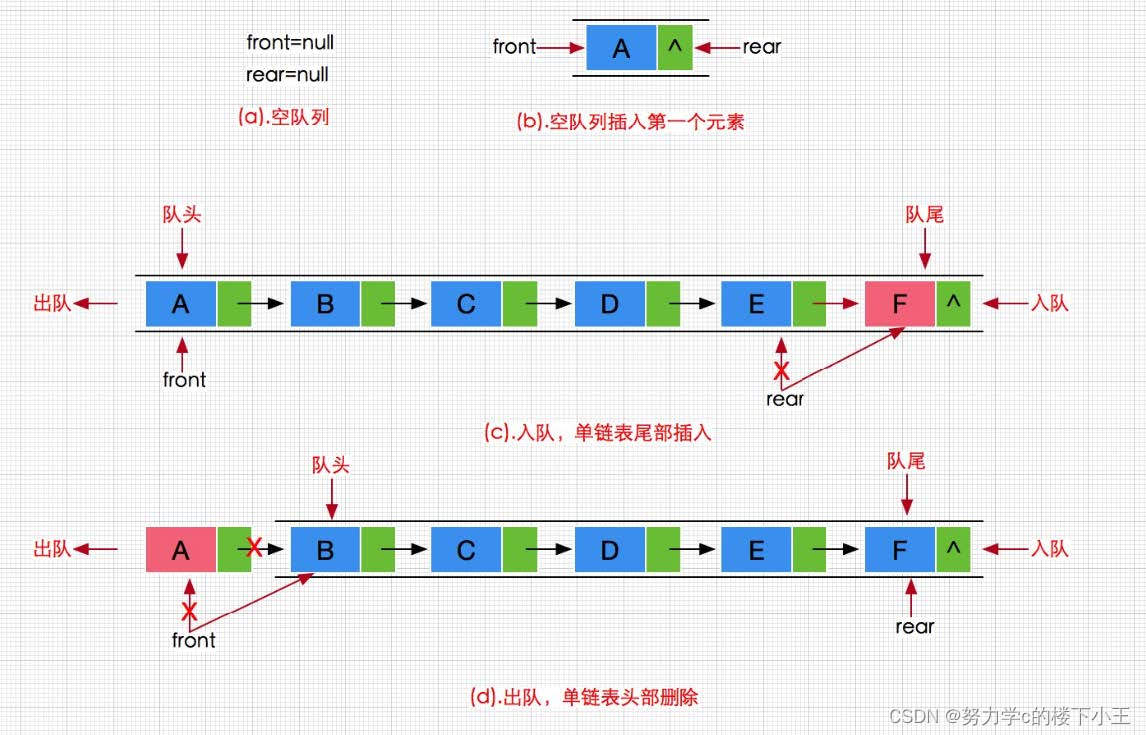
//初始化
void QueueInit(Queue* pq);
//销毁
void QueueDestory(Queue* pq);
//尾入数据
void QueuePush(Queue* pq, QDataType x);
//头出数据
void QueuePop(Queue* pq);
//取队头的数据
QDataType QueueFront(Queue* pq);
//取队尾的数据
QDataType QueueBack(Queue* pq);
//判断是否为空
bool QueueEmpty(Queue* pq);
//计算队列中的元素
int QueueSize(Queue* pq);
代码实现
定义队列基本结构
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType data;
}QNode;
typedef struct Queue
{
//定义两个指针,tail方便尾插
//方便对头出数据,尾入数据
QNode* head;
QNode* tail;
}Queue;
1,初始化
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
}
2, 销毁
void QueueDestory(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->head = pq->tail = NULL;
}
这段代码实现了队列的销毁操作。
它接受一个指向队列的指针 pq,并通过遍历队列中的每个节点来逐个释放它们的内存。
首先,它在 assert 语句中检查指针 pq 是否为空,以确保操作的安全性。
然后,它将队列的头指针 pq->head 赋值给局部变量 cur,作为遍历的起始点。
接下来使用一个循环来遍历队列的每个节点。在每次循环中,它首先将当前节点 cur 的下一个节点保存在指针变量 next 中,以便能够继续遍历队列。
然后,它使用 free 函数释放当前节点 cur 的内存。
最后,它将 cur 更新为 next,以便在下一次循环中继续遍历。在循环结束后,它将队列的头指针 pq->head 和尾指针 pq->tail 都设为 NULL,表示队列已经为空了。
这段代码确保了在销毁队列后,所有节点的内存都得到了正确的释放,以避免内存泄漏。
3,尾入数据
void QueueDestory(Queue* pq)
{
assert(pq);
//QNode* cur = pq->head;`:创建一个指针 `cur`,
//并将其初始化为指向队列的头节点。这将是遍历队列的起点
QNode* cur = pq->head;
while (cur)
{
//创建一个指针 `next`,将其指向当前节点 `cur` 的下一个节点。
//这是为了保留对下一个节点的引用,以便在释放当前节点后继续访问。
QNode* next = cur->next;
free(cur);
cur = next;
}
//在循环结束后,将队列的头指针 `pq->head`
//和尾指针 `pq->tail` 都设置为 NULL,表示队列为空。
pq->head = pq->tail = NULL;
}
4,头出数据
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
/*1,只有一个头节点
2,多个节点*/
//判断队列是否只有一个节点。如果队列只有一个节点,即头节点,进入 `if` 语句。
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
//创建一个指针 `next`,将其指向头节点的下一个节点。
QNode* next = pq->head->next;
free(pq->head);
//将指针 `pq->head` 更新为 `next`,即将头指针指向下一个节点。
pq->head = next;
}
}
5,取队头的数据
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
6,取队尾的数据
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
7,判断是否为空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->head == NULL;
}
8,计算队列中的元素
int QueueSize(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
int size = 0;
while (cur)
{
++size;
cur = cur->next;
}
return size;
}
此处是单独创建一个函数进行计算队列中的元素个数
另一种方法是在定义队列基本结构的结构体中定义一个int size
每次尾增时++size
每次头删时–size
成品
Queue.h
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType data;
}QNode;
typedef struct Queue
{
//定义两个指针,tail方便尾插
//方便对头出数据,尾入数据
QNode* head;
QNode* tail;
}Queue;
//初始化
void QueueInit(Queue* pq);
//销毁
void QueueDestory(Queue* pq);
//尾入数据
void QueuePush(Queue* pq, QDataType x);
//头出数据
void QueuePop(Queue* pq);
//取队头的数据
QDataType QueueFront(Queue* pq);
//取队尾的数据
QDataType QueueBack(Queue* pq);
//判断是否为空
bool QueueEmpty(Queue* pq);
//计算队列中的元素
int QueueSize(Queue* pq);
Queue.c
#include "Queue.h"
//初始化
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
}
//销毁
void QueueDestory(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->head = pq->tail = NULL;
}
//尾入数据
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
if (pq->tail == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
}
//头出数据
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
//1,只有一个头节点
//2,多个节点
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* next = pq->head->next;
free(pq->head);
pq->head = next;
}
}
//取队头的数据
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
//取队尾的数据
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
//判断是否为空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->head == NULL;
}
//计算队列中的元素
int QueueSize(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
int size = 0;
while (cur)
{
++size;
cur = cur->next;
}
return size;
}
test.c
test.c只是用于测试代码,菜单的写法本文将不进行讲解。
但test.c中含有对查找and销毁and存储链元素个数的使用方法进行了示例可以当参考。
#include "Queue.h"
void test()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));
QueuePop(&q);
}
printf("\n");
QueueDestory(&q);
}
int main()
{
test();
return 0;
}









