一. 分布式文件版本管理系统
在分布式文件版本管理系统到来之前,市面上的文件版本管理软件都是集中式的(svn 就是典型的集中式文件版本管理系统),其软件会分为客户端软件和服务端软件两个部分,服务端软件主要功能是管理,比如对我们提交的文件的版本、分支等信息进行集中保存和管理,客户端软件主要功能是操作,比如从服务端中拉取文件、提交修改后的文件到服务端等,如下图:

集中式的管理有个致命的缺点,文件版本信息都在服务器端保存管理,一旦服务器坏了,这些管理信息就丢失了,丢失了会有什么影响呢,简单的一个例子,线上代码出问题了,需要回滚到之前的版本,那这个需求就无法实现
基于上述缺点,分布式文件版本管理系统出现了,其软件不再有客户端和服务端之分,不再是客户端操作后,请求服务端对操作进行记录、对版本进行管理的模式了,而是对文件操作后,直接在本地进行版本的管理和操作的记录,最后再将修改的文件和版本管理信息一并推送到远端。从远端拉取时也不仅仅是拉取文件,还会拉取完整的版本信息
这里需要注意的是,分布式模式中本地和远端的关系,不同于集中式中客户端和服务端的关系,集中式模式中客户端和服务端的功能是不一样的,而分布式模式中本地和远端的功能是相同的,远端只是另一台安装了分布式版本管理软件的机器(甚至可以是相同机器的不同路径),可以理解为本地和远端只是相对的叫法,每一个本地都可以成为另一个本地的远端

上图就是一个分布式系统的基础模型,图中也体现出了任何一个本地都可以是另一个本地的远端的结论,站在机器B的角度来说,机器B就是本地,机器A就是远端,站在机器C的角度来说机器C就是本地,机器B就是远端。
在这种分布式模式下,当机器A坏了,并不会影响机器B,因为从机器A拉取时,机器B已经包含了完整的版本信息,假设线上代码出现问题并且机器A坏了,这时机器B可以直接根据本地版本信息进行回滚,并将新的版本信息记录到本地,然后将回滚后的代码发布即可解决问题,最后等机器A恢复时,再将本地的版本信息推送给机器A保持本地和远端信息同步
二、Git 介绍
Git 是一个经典的分布式文件版本管理系统,后面的篇幅,将对 Git 作一个简单的介绍,Git 官网
2.1. Git 的最基本使用
在开始使用 Git 前,我们首先要知道 Git 的分区结构,因为 Git 的基本操作,都是围绕着分区来进行的,前面已经介绍过在分布式模式中,本地和远端的功能与结构是一样的,接下来就站在本地的角度介绍 Git 中的三大分区,如下图:
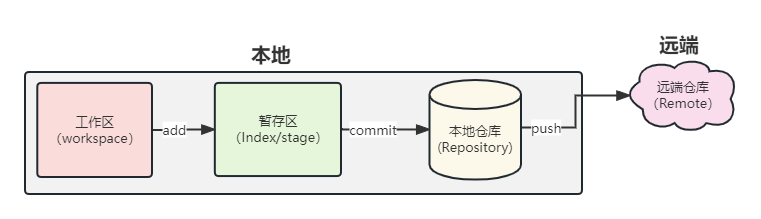
- 工作区:编写文件的地方,编写后需要通过
git add命令添加到暂存区 - 暂存区:将编写后的文件暂存的地方,这里的文件可以通过
git commit命令提交到仓库中 - 本地仓库(仓库):包含文件和文件版本等信息,可以通过
git push命令将文件和信息推送到远端
对 Git 的分区有个大概了解后,就可以开始演示最基本的 Git 操作流程了
1. 新建 Git 仓库
(1)在想要创建 Git 仓库的地方,打开 git 命令行工具:

(2)如果是首次使用 Git,我们需要设置一下 Git 的用户名和邮箱,这个用户名和邮箱的作用就是别人查看提交历史时,可以知道是谁提交的,联系方式是什么,没有别的意义。直接在 Git 命令行窗口输入如下命令:
git config --global user.name "用户名"
git config --global user.email "邮箱地址"
(3)前置准备做好了, 可以开始创建 Git 仓库了,利用下面命令:
git init 仓库名
创建成功后,就会在打开 Git 命令行的目录多出一个新建的目录,这个目录就是 Git 仓库,其内部结构如下:

2. 在工作区添加文件
有了 Git 仓库后,我们就可以在仓库的工作区创建文件了,添加一个文件,如下图:

文件创建后,我们通过 git status 命令,来查看一下 Git 仓库状态:

此时,Git 仓库的状态提示是 Untracked files ,意思是,工作区中有文件还未被添加到暂存区
3. 将工作区的文件添加到暂存区
当 Git 仓库的状态提示是 Untracked files 时,我们需要将工作区的文件添加到暂存区,命令如下:
git add 文件名
添加到暂存区的命令执行后,再次通过 git status 命令,来查看一下 Git 仓库状态:
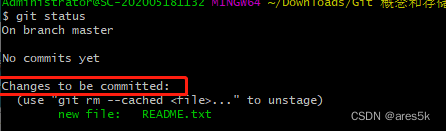
此时,Git 仓库的状态提示是 Changes to be committed ,意思是,暂存区中有文件还未被提交到仓库
4. 将暂存区的文件提交到仓库
当 Git 仓库的状态提示是 Changes to be committed 时,需要将暂存区的文件提交到仓库,命令如下:
git commit -m '注释' 文件名
提交到仓库的命令执行后,再次通过 git status 命令,来查看一下 Git 仓库状态:

此时,Git 仓库的状态提示是 nothing to commit, working tree clean ,代表所有文件已全部提交到仓库
至此,一个本地仓库的最基本操作流程就已经演示完成了,至于其他更多操作,分支、回滚、远端推送、克隆等命令,在其他文章中均有记录
2.2. 工作中使用版本管理工具的经验
先说说是不是一定要用分布式
其实通过上面演示可以感觉出来 Git 的操作与集中式的 Svn 相比是比较繁琐的,所以工作中,不一定就非得要选择 Git 作为版本管理工具,要根据实际需求来决定
如果使用版本管理工具的目的只是为了将文件共享给其他人,而不太在意分支、版本等功能,其实选择 Svn 是可以的,我分享一下我在工作中对版本管理工具的选择经验
- 集中式(svn):我会用其管理项目进度表、需求说明书等文档类的东西,因为这类东西只是为了共享给组员看,对版本信息、分支信息等功能没有什么需求,还有重要的一点,一般这类都是 Office 文件,属于二进制文件,而 Git 不适合管理二进制文件
- 分布式(git):我会用其来管理代码,因为代码经常设计到分支、版本等功能,所以必须保证其容灾性,如果选择集中式软件,那么服务器宕了,会有很大影响,还有一点就是代码都是纯文本文件,Git 适合管理纯文本文件
使用 Git 最好搭配图形化工具
完全通过代码命令来使用 Git,不仅效率低,而且巨难受,所以推荐搭配图形化工具来操作 Git,图形化工具我感觉还可以分为两类,一类适合用作本地,一类适合用作远端
- 适合用作本地的:SmartGit、Sourcetree、TortoiseGit 等
- 使用用作远端的:GitHub、GitLab、Gogs 等
(1)先说说这两类工具的区别:
SmartGit 等工具只是单纯的操作 Git 仓库,仓库的存放目录是我们自己决定的
GitLab 等工具是用来集中管理所有 Git 仓库的,通过 GitLab 创建的 Git 仓库的存放目录是由 GitLab 内部来管理的,我们无法控制,最终 GitLab 会生成一个用于克隆的地址
(2)再说一下实际工作中怎么搭配使用这两类工具:
实际项目中,负责人会在服务器上用 GitLab 创建 Git 仓库,然后组员将仓库克隆到本地后,再通过 SmartGit 操作
这里有必要说一下,身边很多人认为,只有通过 GitLab 等工具创建出来的仓库才能当作远端,其实不是这样的,这些工具只是辅助工具,就算什么工具也不用,单纯的通过 Git 命令创建一个仓库,这个仓库仍可以成为远端。之所以会被迷惑,是因为 GitLab 等工具创建 Git 仓库后,会返回一个仓库的克隆路径。而使用命令创建的仓库,他们不知道仓库的克隆路径是什么,所以就感觉通过命令创建的仓库不能当作远端。我这就列举下通过命令创建的 Git 仓库当作远端时的克隆路径:
# 前面提到过,Git 仓库当作远端有两种场景,第一种是跨路径,第二种是跨机器
# 第一种的克隆路径:
git clone 远端仓库在本机中的路径
# 第二种的克隆路径:
git clone ssh://远端仓库所在机器的登录名@远端仓库所在机器的IP/远端仓库在所在机器中的存放路径
2.3. Git 的存储方式简介
网上有很多对内部存储结构进行超详细解析的,感兴趣可以自行搜索,本文只是大概作一个介绍
本文通过下图的项目目录结构,介绍 Git 的内部存储结构:
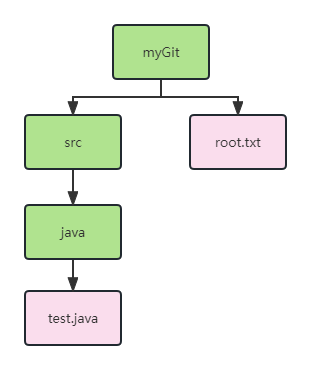
使用 git commit 提交后,Git 会生成 commit、tree、blob 三个对象
- blob:存储原文件的内容
- tree:一个树形结构,这个树形其实就是和我们项目目录相对应,内部保存 blob 地址或下一层 tree 的地址
- commit:内部保存项目根目录的 tree 地址
上文提交后,Git 生成的三个对象的结构如下图:

有了这个结构,当需要回滚时,只需找到目标 commit 地址,就可以回滚整个项目历史版本










