
#include<iostream>
#include<vector>
using namespace std;
int main()
{
string text1,text2;
while(cin>>text1>>text2)
{
//创建二维数组dp,行数text1.size()+1,列数text2.size()+1,并全部初始化为0
vector<vector<int>>dp=vector<vector<int>>(text1.size()+1,vector<int>(text2.size()+1,0)); ;
for(int i=1;i<=text1.size();i++)
{
for(int j=1;j<=text2.size();j++)
{
if(text1[i-1]==text2[j-1])
{
dp[i][j]=dp[i-1][j-1]+1;
}
else
{
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
}
}
}
cout<<dp[text1.size()][text2.size()]<<endl;
}
return 0;
}
1. 确定dp数组(dp table)以及下标的含义
dp[i][j]:⻓度为[0, i - 1]的字符串text1与⻓度为[0, j - 1]的字符串text2的最⻓公共⼦序列为dp[i][j]有同学会问:为什么要定义⻓度为[0, i - 1]的字符串text1,定义为⻓度为[0, i]的字符串text1不⾹么?这样定义是为了后⾯代码实现⽅便,如果⾮要定义为⻓度为[0, i]的字符串text1也可以,我在 动态规划: 718. 最⻓重复⼦数组 中的「拓展」⾥ 详细讲解了区别所在,其实就是简化了dp数组第⼀⾏和第⼀列的初始化逻辑。
2. 确定递推公式
主要就是两⼤情况: text1[i - 1] 与 text2[j - 1]相同, text1[i - 1] 与 text2[j - 1]不相同
如果text1[i - 1] 与 text2[j - 1]相同,那么找到了⼀个公共元素,所以dp[i][j] = dp[i - 1][j - 1] + 1;
如果text1[i - 1] 与 text2[j - 1]不相同,那就看看text1[0, i - 2]与text2[0, j - 1]的最⻓公共⼦序列 和 text1[0, i - 1]与text2[0, j - 2]的最⻓公共⼦序列,取最⼤的。
即: dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);代码如下
if (text1[i - 1] == text2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}3. dp数组如何初始化
先看看dp[i][0]应该是多少呢?
test1[0, i-1]和空串的最⻓公共⼦序列⾃然是0,所以dp[i][0] = 0
同理dp[0][j]也是0。
其他下标都是随着递推公式逐步覆盖,初始为多少都可以,那么就统⼀初始为0。
代码:
vector<vector<int>> dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));4. 确定遍历顺序
从递推公式,可以看出,有三个⽅向可以推出dp[i][j],如图
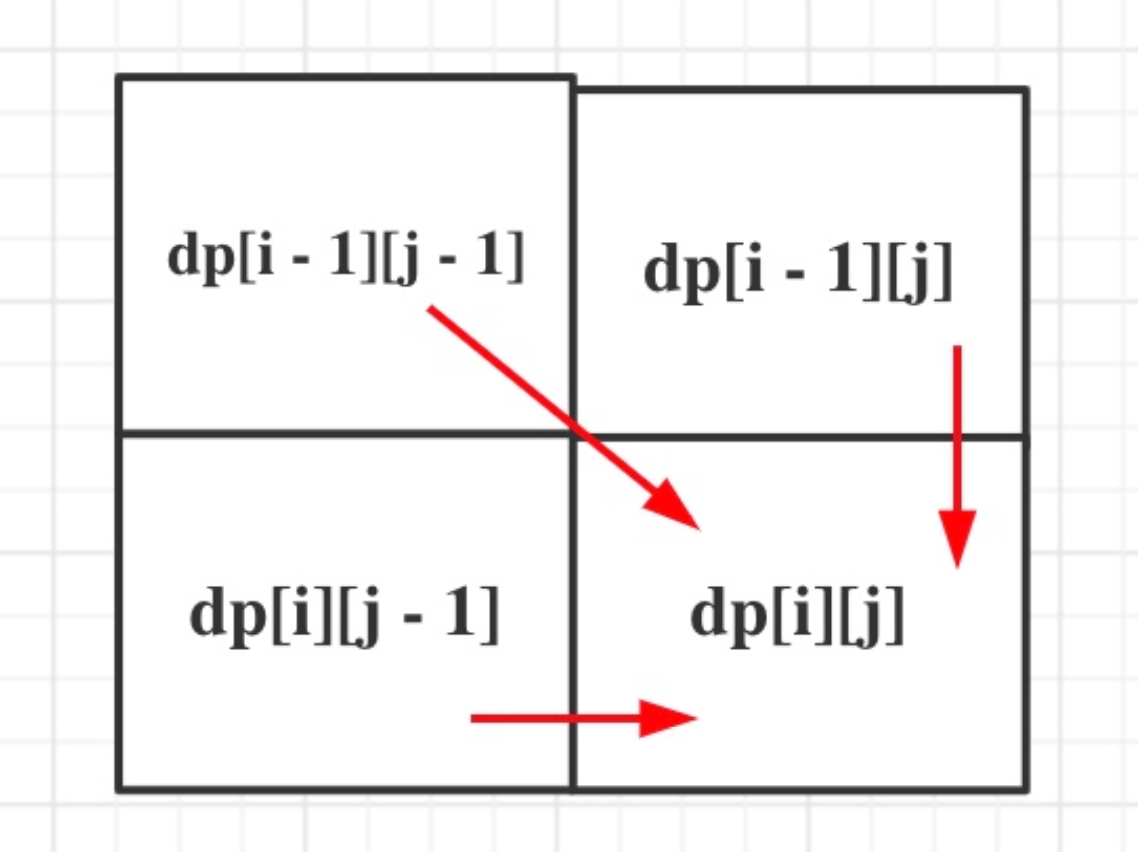
那么为了在递推的过程中,这三个⽅向都是经过计算的数值,所以要从前向后,从上到下来遍历这个矩阵。
5. 举例推导dp数组
以输⼊: text1 = "abcde", text2 = "ace" 为例, dp状态如图:
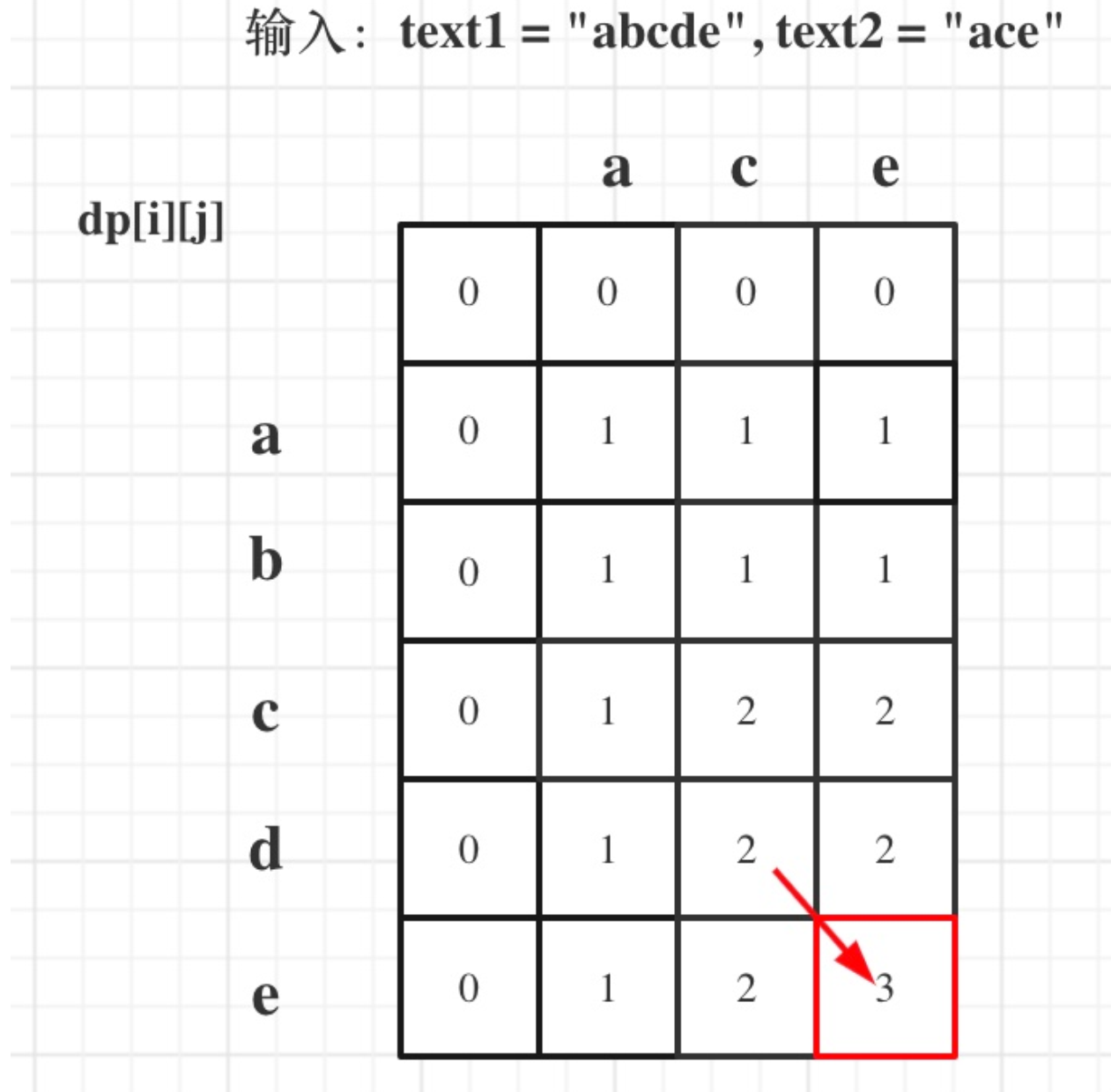
最后红框dp[text1.size()][text2.size()]为最终结果
时间复杂度: O(n * m),其中 n 和 m 分别为 text1 和 text2 的⻓度
空间复杂度: O(n * m)








