供应链是生产和向客户交付货物所涉及的生产和物流网络。供应链分析是指分析供应链的各个组成部分,以了解如何提高供应链的有效性,为客户创造更多价值。所以,如果你想学习如何分析供应链,这篇文章是给你的。文章中,将带你完成使用Python进行供应链分析的任务。
使用Python进行供应链分析
导入必要的Python库和数据集开始供应链分析的任务:
import pandas as pd
import plotly.express as px
import plotly.io as pio
import plotly.graph_objects as go
pio.templates.default = "plotly_white"
data = pd.read_csv("sup
输出
Product type SKU Price Availability Number of products sold \
0 haircare SKU0 69.808006 55 802
1 skincare SKU1 14.843523 95 736
2 haircare SKU2 11.319683 34 8
3 skincare SKU3 61.163343 68 83
4 skincare SKU4 4.805496 26 871
Revenue generated Customer demographics Stock levels Lead times \
0 8661.996792 Non-binary 58 7
1 7460.900065 Female 53 30
2 9577.749626 Unknown 1 10
3 7766.836426 Non-binary 23 13
4 2686.505152 Non-binary 5 3
Order quantities ... Location Lead time Production volumes \
0 96 ... Mumbai 29 215
1 37 ... Mumbai 23 517
2 88 ... Mumbai 12 971
3 59 ... Kolkata 24 937
4 56 ... Delhi 5 414
Manufacturing lead time Manufacturing costs Inspection results \
0 29 46.279879 Pending
1 30 33.616769 Pending
2 27 30.688019 Pending
3 18 35.624741 Fail
4 3 92.065161 Fail
Defect rates Transportation modes Routes Costs
0 0.226410 Road Route B 187.752075
1 4.854068 Road Route B 503.065579
2 4.580593 Air Route C 141.920282
3 4.746649 Rail Route A 254.776159
4 3.145580 Air Route A 923.440632
[5 rows x 24 columns]
让我们来看看数据集的描述性统计:
print(data.describe())
输出
Price Availability Number of products sold Revenue generated \
count 100.000000 100.000000 100.000000 100.000000
mean 49.462461 48.400000 460.990000 5776.048187
std 31.168193 30.743317 303.780074 2732.841744
min 1.699976 1.000000 8.000000 1061.618523
25% 19.597823 22.750000 184.250000 2812.847151
50% 51.239831 43.500000 392.500000 6006.352023
75% 77.198228 75.000000 704.250000 8253.976921
max 99.171329 100.000000 996.000000 9866.465458
Stock levels Lead times Order quantities Shipping times \
count 100.000000 100.000000 100.000000 100.000000
mean 47.770000 15.960000 49.220000 5.750000
std 31.369372 8.785801 26.784429 2.724283
min 0.000000 1.000000 1.000000 1.000000
25% 16.750000 8.000000 26.000000 3.750000
50% 47.500000 17.000000 52.000000 6.000000
75% 73.000000 24.000000 71.250000 8.000000
max 100.000000 30.000000 96.000000 10.000000
Shipping costs Lead time Production volumes \
count 100.000000 100.000000 100.000000
mean 5.548149 17.080000 567.840000
std 2.651376 8.846251 263.046861
min 1.013487 1.000000 104.000000
25% 3.540248 10.000000 352.000000
50% 5.320534 18.000000 568.500000
75% 7.601695 25.000000 797.000000
max 9.929816 30.000000 985.000000
Manufacturing lead time Manufacturing costs Defect rates Costs
count 100.00000 100.000000 100.000000 100.000000
mean 14.77000 47.266693 2.277158 529.245782
std 8.91243 28.982841 1.461366 258.301696
min 1.00000 1.085069 0.018608 103.916248
25% 7.00000 22.983299 1.009650 318.778455
50% 14.00000 45.905622 2.141863 520.430444
75% 23.00000 68.621026 3.563995 763.078231
max 30.00000 99.466109 4.939255 997.413450
现在,让我们开始分析供应链,通过查看产品价格与其产生的收入之间的关系:
fig = px.scatter(data, x='Price',
y='Revenue generated',
color='Product type',
hover_data=['Number of products sold'],
trendline="ols")
输出

因此,该公司从护肤产品中获得更多收入,护肤产品的价格越高,其产生的收入越多。现在让我们来看看按产品类型划分的销售情况:
sales_data = data.groupby('Product type')['Number of products sold'].sum().reset_index()
pie_chart = px.pie(sales_data, values='Number of products sold', names='Product type',
title='Sales by Product Type',
hover_data=['Number of products sold'],
hole=0.5,
color_discrete_sequence=px.colors.qualitative.Pastel)
pie_chart.update_trace
输出

以上,45%的业务来自护肤产品,29.5%来自护发产品,25.5%来自化妆品。现在让我们来看看航运公司产生的总收入:
total_revenue = data.groupby('Shipping carriers')['Revenue generated'].sum().reset_index()
fig = go.Figure()
fig.add_trace(go.Bar(x=total_revenue['Shipping carriers'],
y=total_revenue['Revenue generated']))
fig.update_layout(title='Total Revenue by Shipping Carrier',
xaxis_title='Shipping Carrier',
输出

该公司使用三家运营商进行运输,而运营商B帮助该公司创造更多收入。现在让我们来看看该公司所有产品的平均交货期和平均制造成本:
avg_lead_time = data.groupby('Product type')['Lead time'].mean().reset_index()
avg_manufacturing_costs = data.groupby('Product type')['Manufacturing costs'].mean().reset_index()
result = pd.merge(avg_lead_time, avg_manufacturing_costs, on='Product type')
result.rename(columns={'Lead time': 'Average Lead Time', 'Manufacturing costs': 'Average Manufacturing Costs'}, inplace=True)
print(result)
输出
Product type Average Lead Time Average Manufacturing Costs
0 cosmetics 13.538462 43.052740
1 haircare 18.705882 48.457993
2 skincare 18.000000 48.993157
分析SKU
数据集中有一列是SKU。SKU是Stock Keeping Units的缩写。它们就像特殊的代码,帮助公司跟踪他们销售的所有不同的东西。想象一下,你有一个很大的玩具店,里面有很多玩具。每个玩具都不一样,有它的名字和价格,但是当你想知道你还剩多少时,你需要一种方法来识别它们。所以你给予每个玩具一个唯一的代码,就像一个只有商店知道的代码。这个代码被称为SKU。
现在我们来分析一下每个SKU产生的收入:
revenue_chart = px.line(data, x='SKU',
y='Revenue generated',
title='Revenue Generated by SKU')
revenue_chart.show()
输出

数据集中还有一列是库存水平。库存水平是指商店或企业在其库存中的产品数量。现在让我们来看看每个SKU的库存水平:
stock_chart = px.line(data, x='SKU',
y='Stock levels',
title='Stock Levels by SKU')
stock_chart.show()
输出

现在让我们来看看每个SKU的订单数量:
order_quantity_chart = px.bar(data, x='SKU',
y='Order quantities',
title='Order Quantity by SKU')
order_quantity_chart.show()
输出

成本分析
现在让我们来分析运输商的运输成本:
shipping_cost_chart = px.bar(data, x='Shipping carriers',
y='Shipping costs',
title='Shipping Costs by Carrier')
shipping_cost_chart.show()
输出

在上面的一个可视化中,我们发现运营商B帮助公司获得更多收入。它也是这三家航空公司中成本最高的。现在让我们来看看按运输方式的成本分布:
transportation_chart = px.pie(data,
values='Costs',
names='Transportation modes',
title='Cost Distribution by Transportation Mode',
hole=0.5,
color_discrete_sequence=px.colors.qualitative.Pastel)
transportation_chart.show()
输出

因此,该公司在公路和铁路运输方式上花费更多用于货物运输。
分析缺陷率
供应链中的缺陷率指的是产品出货后出现问题或被发现损坏的百分比。让我们来看看所有产品类型的平均缺陷率:
defect_rates_by_product = data.groupby('Product type')['Defect rates'].mean().reset_index()
fig = px.bar(defect_rates_by_product, x='Product type', y='Defect rates',
title='Average Defect Rates by Product Type')
fig.show()
输出

因此护发产品的缺陷率较高。现在让我们看看运输方式的缺陷率:
pivot_table = pd.pivot_table(data, values='Defect rates',
index=['Transportation modes'],
aggfunc='mean')
transportation_chart = px.pie(values=pivot_table["Defect rates"],
names=pivot_table.index,
title='Defect Rates by Transportation Mode',
hole=0.5,
color_discrete_sequence=px.colors.qualitative.Pastel)
transportation_chart.show()
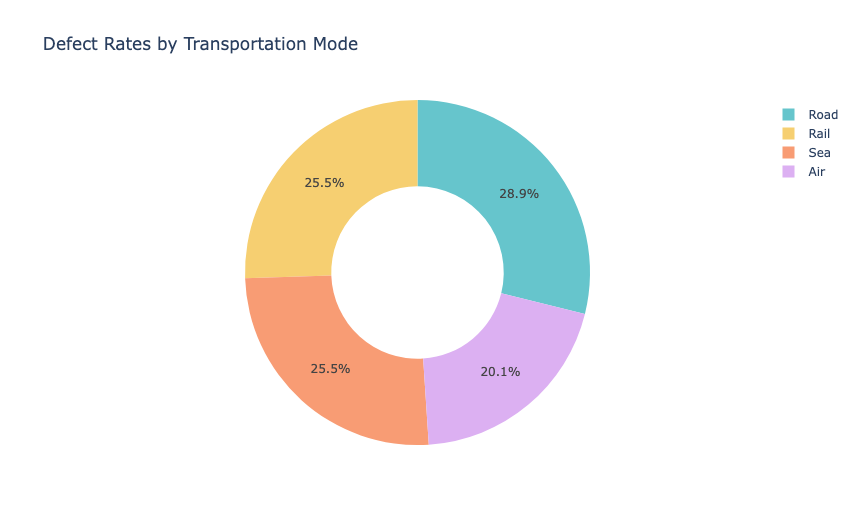
公路运输的缺陷率较高,航空运输的缺陷率最低。
总结
供应链分析是指分析供应链的各个组成部分,以了解如何提高供应链的有效性,为客户创造更多价值。以上是使用Python进行供应链分析的一个实践案例。









